Una sola corrida — y sus límites
Los resultados de esta página provienen de una sola corrida de cada método: 500 episodios, semilla 42, sobre CartPole-v1.
Eso es suficiente para ilustrar los conceptos — pero no para hacer afirmaciones estadísticas. Un solo resultado puede ser afortunado o desafortunado. Para comparar métodos de forma rigurosa, lo correcto es:
- Fijar $k$ semillas distintas (típicamente $k = 10\text{–}30$).
- Reportar media ± desviación estándar de la recompensa promedio en los últimos 100 episodios.
- Aplicar un test estadístico (Mann-Whitney U, por ejemplo) antes de declarar un método “mejor”.
Con esa advertencia clara, miremos lo que sí muestra esta corrida.
Tabla resumen
| Método | Primeros 10 ep (avg) | Últimos 50 ep (avg) | Mejor media móvil 50 ep | Mejor episodio | Cruzó 200 en ep | Cruzó 475 en ep |
|---|---|---|---|---|---|---|
| SARSA | 23.8 | 44.2 | 61.5 | 247 | — | — |
| Q-learning | 19.8 | 64.9 | 70.1 | 290 | — | — |
| DQN | 18.7 | 387.5 | 412.1 | 500 | ep 289 | no alcanzado* |
* La media móvil de 50 episodios cruzó 200 en el episodio 289, 300 en el 307 y 400 en el 480. El umbral oficial de 475 no se cruzó en esta corrida de 500 episodios — DQN lo alcanza típicamente en 400–600 episodios.
Métodos tabulares: el problema de cobertura
Los dos métodos tabulares (SARSA, Q-learning) parten del mismo supuesto: hay una celda en la tabla para cada par $(s, a)$ posible.
Con 10 bins por dimensión, CartPole tiene $10^4 \times 2 = 20{,}000$ pares estado-acción. ¿Cuántos visitó el agente en 500 episodios?
| Método | Pares visitados | Cobertura |
|---|---|---|
| SARSA | 499 / 20 000 | 2.5 % |
| Q-learning | 692 / 20 000 | 3.5 % |
El agente nunca vio el 97 % del espacio de estados.
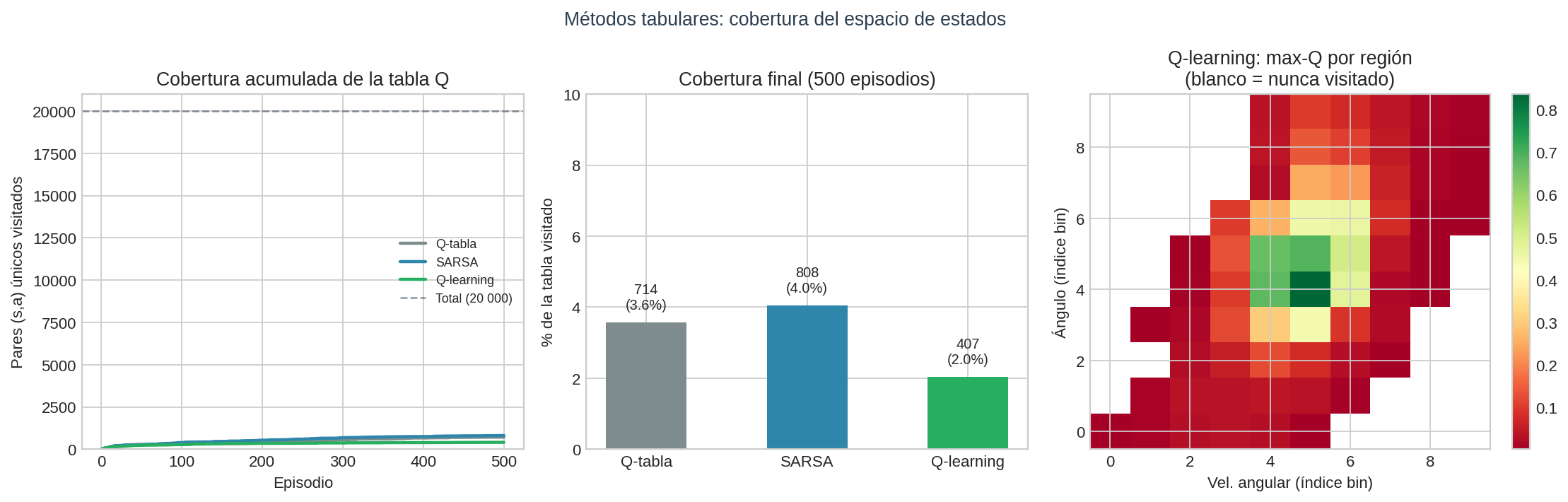
El panel izquierdo muestra cómo crecen los pares visitados por episodio: la curva se aplana rápido, señal de que el agente ya no descubre estados nuevos. El panel central confirma los porcentajes. El panel derecho es el heatmap de la Q-tabla en las dimensiones ángulo × velocidad angular del poste: las celdas blancas son estados que el agente nunca visitó — la mayoría del espacio.
¿Por qué se aplana la recompensa?
Una tabla sin cobertura no puede generalizar. Si el agente aprende que el estado $(θ = 5°, \dot{θ} = 0.3)$ tiene valor alto, eso no dice nada sobre $(θ = 5.1°, \dot{θ} = 0.3)$ — son celdas distintas e independientes. El resultado es la meseta visible en la curva de convergencia: el agente mejora ligeramente al aprender a evitar los peores estados, pero no puede generalizar más allá de los estados que ha visitado.
DQN: tres fases de aprendizaje
DQN comienza igual que los métodos tabulares — recompensas de ~18 en los primeros 10 episodios. La diferencia aparece alrededor del episodio 289.
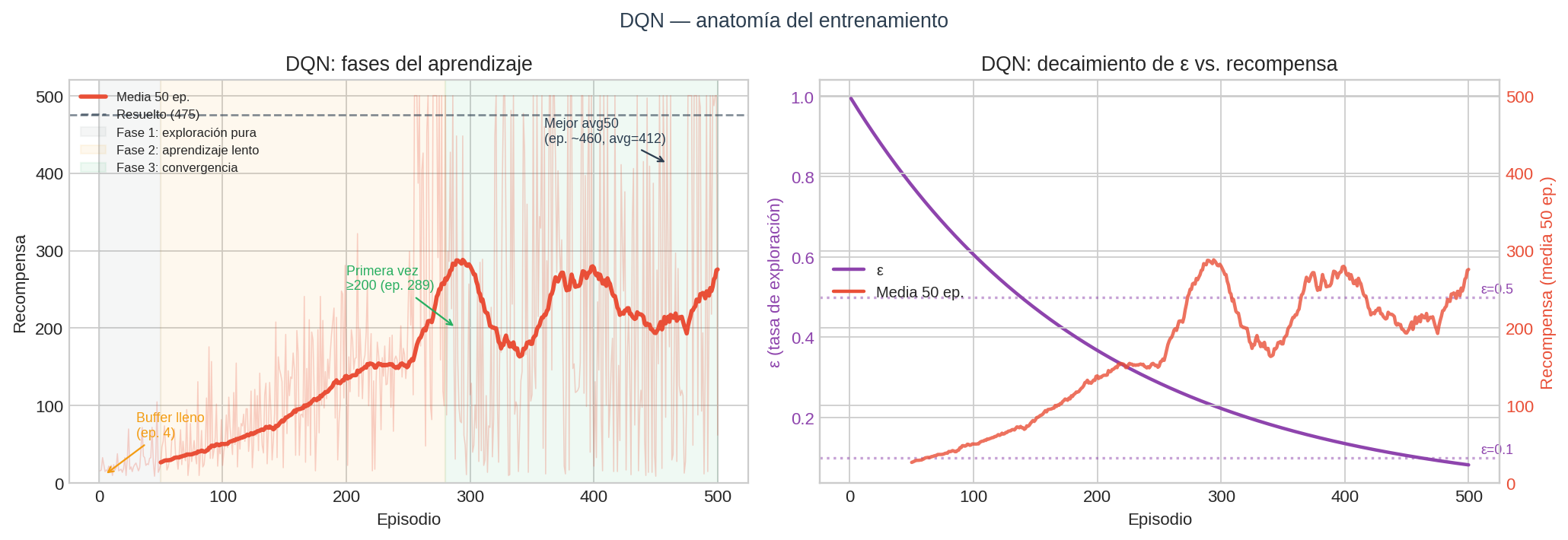
Fase 1 — Exploración pura (episodios 1–50)
$\varepsilon$ empieza en 1.0: el agente actúa completamente al azar. El buffer se llena en el episodio 4 (cuando el agente acumula sus primeras 64 transiciones) y el entrenamiento comienza. Las recompensas oscilan entre 8 y 30 — el poste cae casi de inmediato.
Fase 2 — Aprendizaje lento (episodios 50–280)
$\varepsilon$ cae por debajo de 0.5. La red empieza a aprender correlaciones entre el ángulo del poste y la acción correcta, pero los valores Q aún son ruidosos. La media móvil sube gradualmente de ~20 a ~80.
Fase 3 — Convergencia (episodios 280–500)
En el episodio 289, la media móvil cruza 200 por primera vez. En el 307, cruza 300. La red ha aprendido a generalizar: estados similares producen acciones similares porque comparten los mismos pesos $\theta$. La recompensa alcanza 500 (el máximo posible) en múltiples episodios.
La curva de pérdida: ¿por qué sube?
La pérdida MSE de DQN al inicio fue 0.56 y al final 34.6 — un aumento de $\times 62$. Esto parece contradictorio: ¿no debería bajar si el agente está aprendiendo?
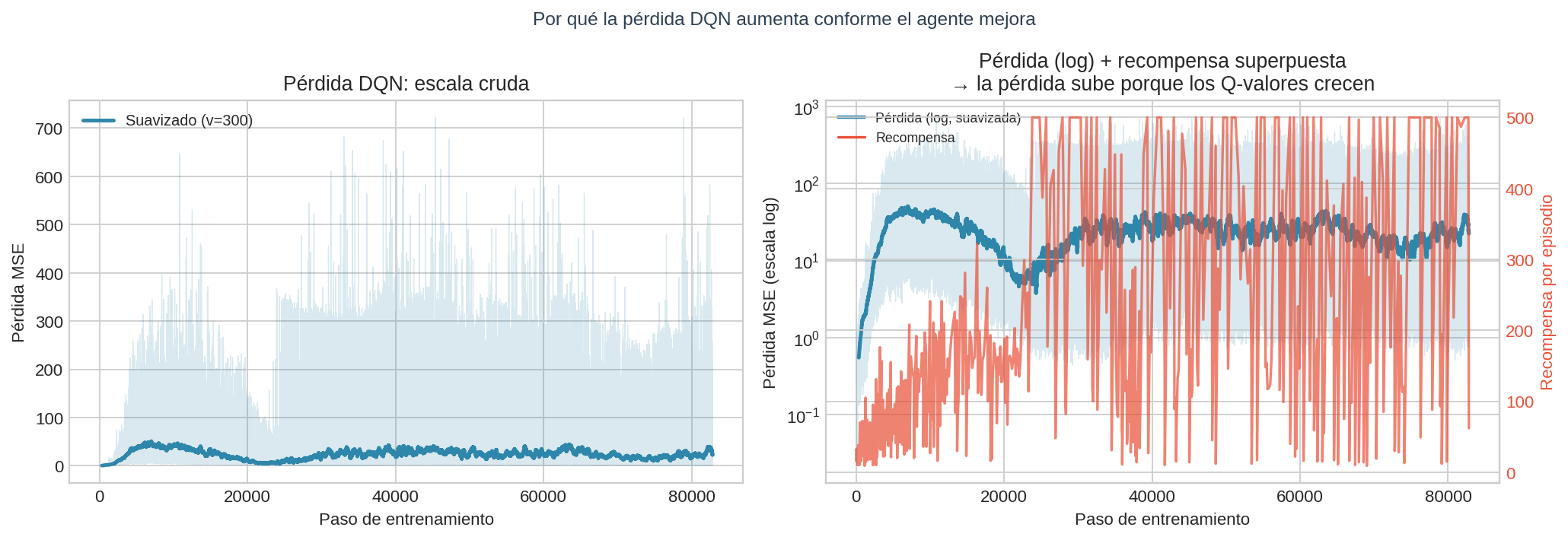
La explicación está en la escala de los valores Q.
Al inicio, un episodio dura ~18 pasos → $Q_\theta(s,a) \approx 18$. Al final, un episodio dura ~400 pasos → $Q_\theta(s,a) \approx 400$.
La pérdida MSE escala con el cuadrado de los valores:
$$L \propto (y_i - Q_\theta)^2$$
Si los valores Q crecen de 18 a 400 (factor $\times 22$), la pérdida puede crecer por factor $\times 22^2 \approx 484$ aunque las predicciones sean igual de precisas en términos relativos.
El panel derecho (escala logarítmica) superpone pérdida y recompensa — ambas suben juntas. El aumento de la pérdida es una consecuencia directa del éxito del agente, no de su fracaso.
Si la pérdida subiera mientras la recompensa baja, eso sería señal de inestabilidad. En este caso ambas suben — el modelo simplemente tiene más por aprender.
Curva de convergencia: los cuatro métodos
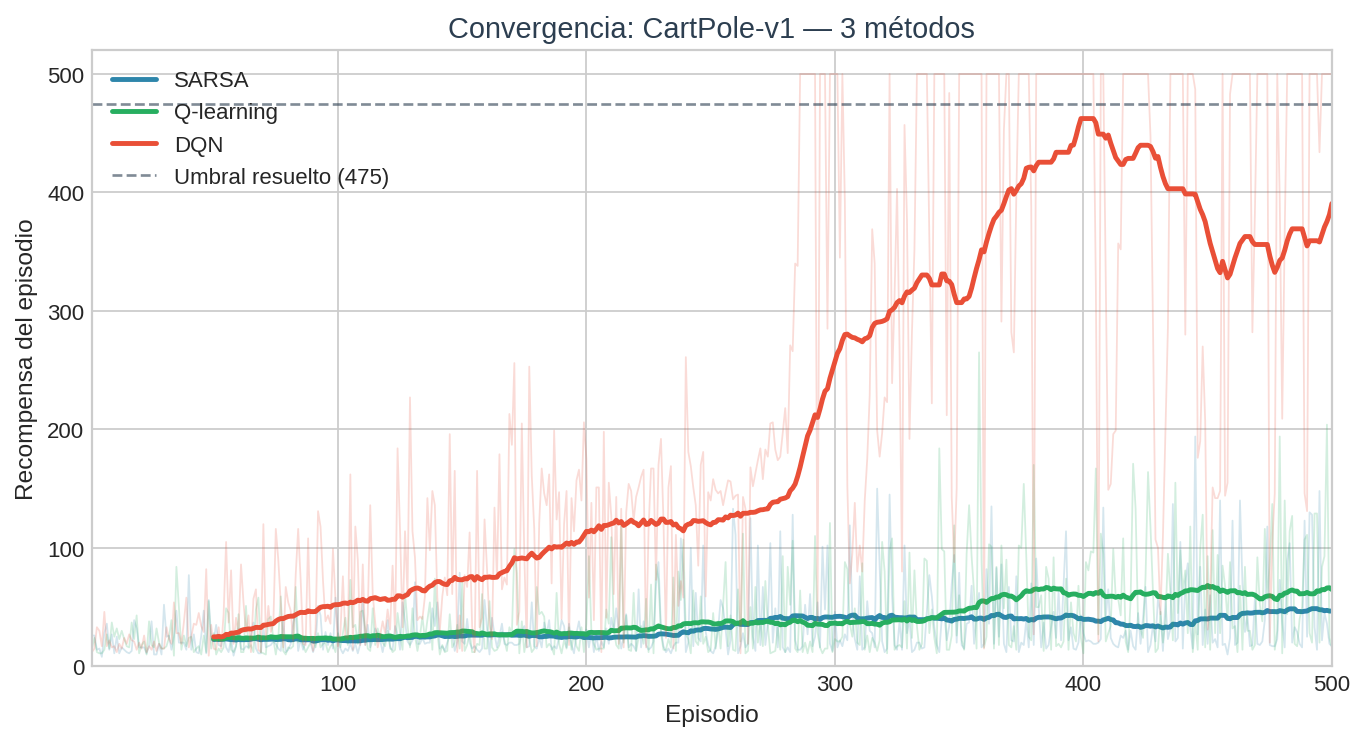
La brecha entre DQN y los métodos tabulares es estructural, no de hiperparámetros. Se podría afinar el número de bins, la tasa de aprendizaje o el decaimiento de $\varepsilon$ de los métodos tabulares — y mejorarían algo. Pero el límite fundamental es la cobertura: con 500 episodios, el agente tabular no puede explorar el $97%$ del espacio de estados que nunca visitó.
DQN no tiene ese límite porque los pesos $\theta$ son compartidos: aprender algo sobre el estado $(θ = 5°)$ actualiza implícitamente la estimación para $(θ = 5.1°)$. Esa generalización es la ventaja decisiva de la aproximación de funciones.
Diferencias entre los métodos tabulares
Q-learning obtiene la mejor recompensa final (64.9 vs 44.2 de SARSA).
Esto es consistente con la teoría:
- Q-learning aprende $Q^∗$ directamente (off-policy, usa $\max_b Q(s’,b)$) — extrae el máximo valor posible de cada transición, independientemente de la política que la generó.
- SARSA aprende $Q^{\pi_\varepsilon}$ (on-policy, usa $Q(s’,a’)$ con $a’ \sim \pi_\varepsilon$) — el valor de la política que ejecuta, incluyendo el ruido de exploración.
La ventaja de Q-learning sobre SARSA se amplifica cuando $\varepsilon$ es alto (mucha exploración), porque SARSA “contamina” su target con acciones exploratorias. Con $\varepsilon \to 0$ ambos convergen al mismo resultado.
Lo que diría un experimento completo
Con $k = 20$ semillas distintas, esperaríamos ver:
| Resultado esperado | Razón |
|---|---|
| Métodos tabulares con mayor varianza episodio a episodio | Menos suavizado por generalización |
| DQN resolviendo CartPole (≥ 475) en 400–600 eps en la mayoría de corridas | La generalización estabiliza el aprendizaje |
| SARSA ligeramente por debajo de Q-learning en la mayoría de corridas | Contamina el target con exploración |
| Q-learning con más picos bajos que SARSA en entornos peligrosos | Aprende el camino óptimo aunque la exploración lo haga caer |
Si quieres ejecutar el experimento completo, el script run_stats.py en deep_rl/ sirve como punto de partida: basta con iterar sobre semillas y agregar los resultados.