Configuración del entorno
El laboratorio está en el directorio deep_rl/ dentro del módulo.
Todo el código está autocontenido: un script de setup crea el entorno virtual e instala las dependencias (PyTorch CPU, Gymnasium, Matplotlib, tqdm).
# Desde la raíz del repositorio
cd clase/23_reinforcement_learning/deep_rl
# Instalar dependencias (una sola vez)
./setup.sh
# Activar el entorno virtual
source .venv/bin/activate
# Ejecutar el demo
python demo_cartpole.py --method dqn
El script setup.sh crea .venv/, instala las dependencias con pip e imprime el comando de activación al terminar.
No requiere CUDA — todo corre en CPU.
El entorno: CartPole-v1
El MDP completo
| Símbolo | Nombre | Valor |
|---|---|---|
| $S$ | Espacio de estados | Vector continuo 4D: $(x,\ \dot{x},\ \theta,\ \dot{\theta})$ |
| — $x$: posición del carro | $[-4.8,\ 4.8]$ metros | |
| — $\dot{x}$: velocidad del carro | $(-\infty, +\infty)$ m/s | |
| — $\theta$: ángulo del poste | $[-24°,\ 24°]$ | |
| — $\dot{\theta}$: velocidad angular | $(-\infty, +\infty)$ rad/s | |
| $A(s)$ | Acciones | ${0=\text{izquierda},\ 1=\text{derecha}}$ |
| $R(s,a,s’)$ | Recompensa | $+1$ por cada paso sin caída |
| Terminal | Condición de fin | $\lvert\theta\rvert > 12°$ o $\lvert x \rvert > 2.4$ o $t > 500$ |
| Resuelto | Criterio oficial | Media $\geq 475$ sobre 100 episodios consecutivos |
La recompensa máxima posible por episodio es 500 (si el poste aguanta 500 pasos exactos). Un agente aleatorio dura típicamente 10-20 pasos.
Los tres métodos en comparación
| Método | Representación del estado | Tipo de política | ¿Converge en CartPole? | Episodios aprox. para resolver |
|---|---|---|---|---|
| SARSA | Discretizado $10^4$ bins | $\varepsilon$-greedy on-policy | Apenas (plateau ~50-80) | No resuelve |
| Q-learning | Discretizado $10^4$ bins | $\varepsilon$-greedy off-policy | Apenas (plateau ~50-80) | No resuelve |
| DQN | Continuo (4 valores reales) | $\varepsilon$-greedy sobre $Q_\theta$ | Sí | ~300-400 episodios |
Los dos métodos tabulares usan 10 bins por dimensión → $10 \times 10 \times 10 \times 10 = 10{,}000$ estados discretos. La discretización pierde información: dos estados con ángulos de $11.9°$ y $12.1°$ caen en bins distintos y reciben valores $Q$ completamente independientes. DQN no discretiza — procesa los 4 valores directamente y puede interpolar entre estados similares.
¿Qué observar en la demo?
Modo un método
python demo_cartpole.py --method dqn
Se abre una ventana con dos paneles: la animación del entorno (carro y poste en tiempo real) y la curva de recompensa episodio a episodio.
Recompensa creciente: Los primeros episodios duran 10-20 pasos — el agente actúa casi al azar. Hacia el episodio 300-400 (con DQN), la curva sube hacia 475. Con los métodos tabulares, la curva sube un poco y luego se estanca.
Decaimiento de $\varepsilon$: $\varepsilon$ comienza en 1.0 (exploración pura) y decae hasta 0.05. Mientras $\varepsilon > 0.5$, la animación se ve caótica — el agente explora sin estrategia. Cuando $\varepsilon < 0.2$, empieza a verse el comportamiento equilibrante: el carro se mueve suavemente para mantener el poste.
Pérdida MSE (solo DQN): La pérdida empieza en valores altos (~10-100) cuando la red no sabe nada. A medida que aprende, baja hacia ~1-5. Una pérdida que no baja es señal de que la tasa de aprendizaje es demasiado alta o el buffer de replay es demasiado pequeño.
Modo comparación
python demo_cartpole.py --compare --episodes 300
Los tres métodos corren en secuencia. Al final se muestra un gráfico con la media móvil de 50 episodios para cada uno.
La diferencia es visual e inmediata:
- SARSA y Q-learning forman dos líneas planas a baja recompensa (~50-80).
- DQN sube continuamente hasta cruzar 475.
Comparación de convergencia
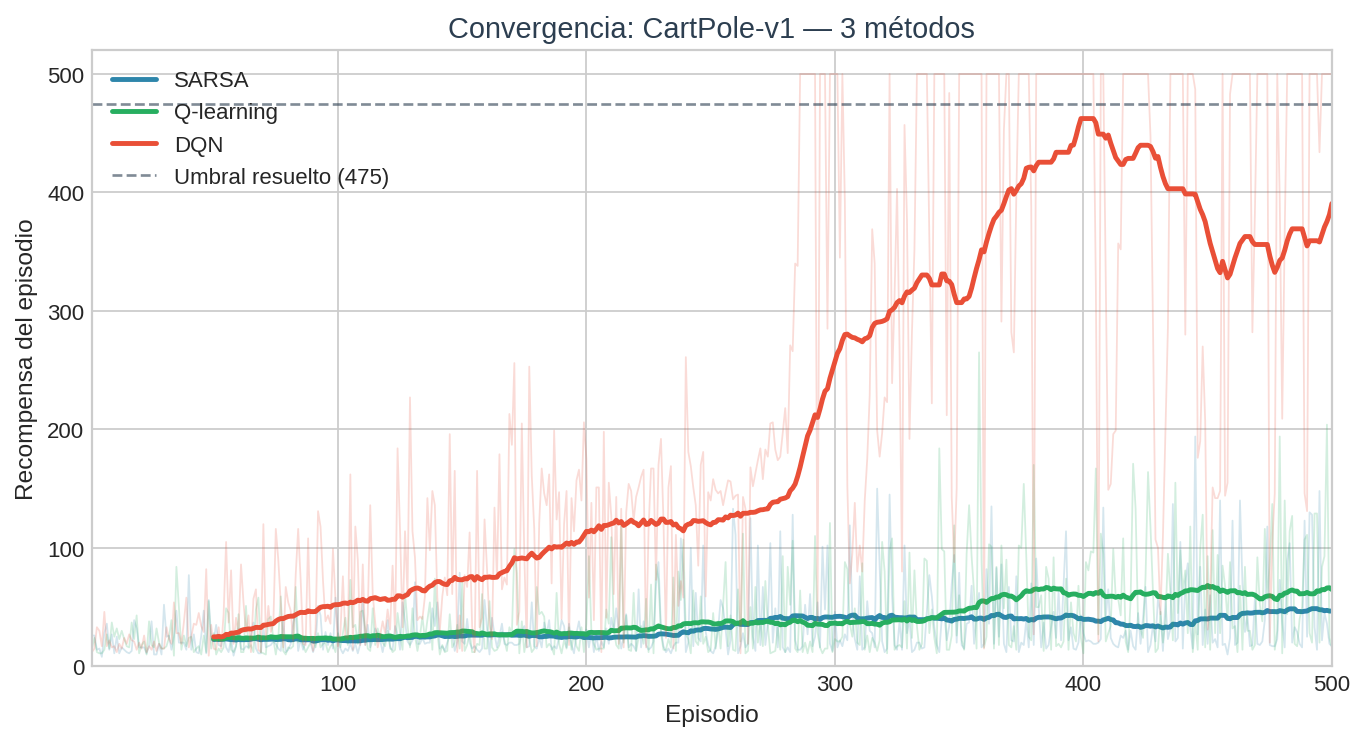
Los dos métodos tabulares se estabilizan en recompensas bajas porque la discretización pierde información crítica. Dos estados con ángulos similares se tratan como completamente distintos, así que el agente no puede generalizar. DQN, al operar sobre el vector continuo, aprende que estados similares tienen valores similares — la red interpola de forma natural porque comparte pesos entre todos los estados.
Un episodio resuelto
Cuatro momentos de un episodio resuelto por el agente DQN entrenado. El poste se mantiene casi vertical durante todo el episodio — el agente aprendió a anticipar la caída y corregir antes de que sea irreversible. El comportamiento emergente es notable: el carro se mueve suavemente de lado a lado, haciendo correcciones pequeñas en lugar de reacciones bruscas.
Comandos de referencia
# Un método con ventana live
python demo_cartpole.py --method dqn # DQN — recomendado para ver convergencia
python demo_cartpole.py --method sarsa # SARSA on-policy tabular
python demo_cartpole.py --method qlearning # Q-learning off-policy tabular
# Comparar los 3 métodos (terminal + ventana final)
python demo_cartpole.py --compare --episodes 300
# Ajustar velocidad y duración
python demo_cartpole.py --method dqn --episodes 200 --speed slow # ver animación con detalle
python demo_cartpole.py --method dqn --episodes 500 --speed fast # correr hasta convergencia
Notas sobre tiempos de ejecución:
DQN en CPU tarda ~2-5 minutos para 400 episodios (la red es pequeña: dos capas de 64 unidades).
Los métodos tabulares son más rápidos por episodio pero no convergen — puedes usar --speed fast para saltar la animación y ver solo la curva.
Para explorar más
Si quieres modificar los experimentos, los hiperparámetros están al inicio de demo_cartpole.py:
| Hiperparámetro | Valor por defecto | Efecto |
|---|---|---|
LEARNING_RATE |
1e-3 | Tasa de aprendizaje de la red |
GAMMA |
0.99 | Factor de descuento |
EPSILON_START |
1.0 | Exploración inicial |
EPSILON_END |
0.05 | Exploración mínima |
EPSILON_DECAY |
0.995 | Velocidad de decaimiento de $\varepsilon$ |
BUFFER_SIZE |
10,000 | Capacidad del buffer de replay |
BATCH_SIZE |
64 | Tamaño del mini-lote |
TARGET_UPDATE |
50 | Pasos entre copias al target |
Experimenta con GAMMA = 0.9 (más miope) o TARGET_UPDATE = 5 (target se actualiza más frecuente) y observa cómo cambia la estabilidad del entrenamiento.