Algoritmo de Viterbi
Problema 2 — Decodificación: ¿Cuál fue la secuencia de estados ocultos más probable?
1. ¿En qué se diferencia de Forward?
El algoritmo Forward calcula $P(O \mid \lambda)$ sumando sobre todas las trayectorias posibles:
$$P(O \mid \lambda) = \sum_{\text{todas las trayectorias}} P(O, \text{trayectoria} \mid \lambda)$$
Eso es correcto cuando queremos la probabilidad total. Pero ahora queremos la trayectoria única más probable — no un promedio, sino el máximo:
$$q_1^∗, q_2^∗, \ldots, q_T^∗ = \arg\max_{q_1, \ldots, q_T} P(q_1, \ldots, q_T, O \mid \lambda)$$
El cambio parece pequeño — reemplazamos $\sum$ por $\max$ — pero tiene consecuencias importantes: ahora debemos recordar de dónde vino cada máximo para poder reconstruir el camino al final.
| Forward | Viterbi | |
|---|---|---|
| Operación central | Suma sobre estados anteriores | Máximo sobre estados anteriores |
| Resultado | $P(O \mid \lambda)$ — probabilidad total | Secuencia óptima $q_1^∗, \ldots, q_T^∗$ |
| ¿Necesita backpointers? | No | Sí |
2. Las dos variables de Viterbi
Variable $\delta_t(i)$ — la probabilidad del mejor camino hasta el estado $i$ en el instante $t$:
$$\delta_t(i) = \max_{q_1, \ldots, q_{t-1}} P(q_1, \ldots, q_{t-1}, q_t = i, O_1, \ldots, O_t \mid \lambda)$$
En palabras: de todas las trayectorias que terminan en el estado $i$ en el instante $t$ habiendo generado $O_1, \ldots, O_t$, ¿cuál es la probabilidad de la mejor?
Variable $\psi_t(j)$ — el backpointer: ¿desde qué estado $i$ llegamos a $j$ en el mejor camino?
$$\psi_t(j) = \arg\max_{i} \delta_{t-1}(i) \cdot A_{ij}$$
Los backpointers son la clave para reconstruir la secuencia óptima al final del algoritmo.
3. Inicialización, recursión y backtracking
[P1] Inicialización ($t = 1$):
$$\delta_1(i) = \pi_i \cdot B_{i,O_1} \qquad \text{para todo } i$$
$$\psi_1(i) = 0 \qquad \text{(no hay estado previo en } t=1\text{)}$$
[P2] Recursión ($t = 2, 3, \ldots, T$):
$$\delta_t(j) = \max_{i} \left[\delta_{t-1}(i) \cdot A_{ij}\right] \cdot B_{j,O_t}$$
$$\psi_t(j) = \arg\max_{i} \left[\delta_{t-1}(i) \cdot A_{ij}\right]$$
Nota: $\psi_t(j)$ se calcula sin el factor $B_{j,O_t}$ porque la emisión no afecta cuál estado anterior fue el mejor.
[P3] Terminación y backtracking:
# Encontrar el mejor estado final:
q*[T] = argmax_i δ[T][i]
# Seguir los backpointers hacia atrás:
para t = T-1 hasta 1:
q*[t] = ψ[t+1][ q*[t+1] ]
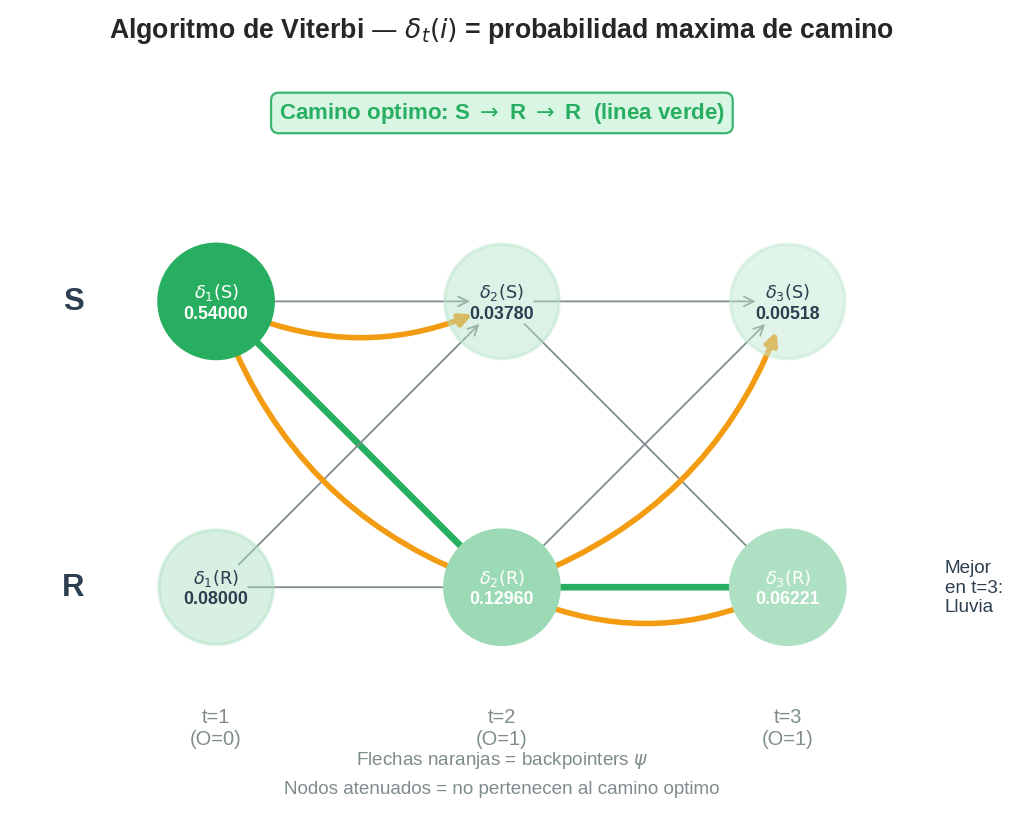
4. Visualización: el trellis de Viterbi
Estado │ t=1 t=2 t=3
───────┼────────────────────────────────────────────────
S │ δ₁(S)=0.540 δ₂(S)=0.0378 δ₃(S)=0.00518
│ ψ₂(S)=S ψ₃(S)=R
│
R │ δ₁(R)=0.080 δ₂(R)=0.1296 δ₃(R)=0.06221
│ ψ₂(R)=S ψ₃(R)=R
O_t │ O₁=0 O₂=1 O₃=1
Mejor estado final: R (δ₃(R)=0.06221 > δ₃(S)=0.00518)
Backtrack: R → ψ₃(R)=R → ψ₂(R)=S
Secuencia óptima: S → R → R
5. Traza completa: el ejemplo de Lain
Parámetros: $\pi = (0.6, 0.4)$, $O = (0, 1, 1)$
$$A = \begin{pmatrix} 0.7 & 0.3 \\ 0.4 & 0.6 \end{pmatrix}, \qquad B = \begin{pmatrix} 0.9 & 0.1 \\ 0.2 & 0.8 \end{pmatrix}$$
Paso 1 — Inicialización ($O_1 = 0$):
$$\delta_1(S) = \pi_S \cdot B_{S,0} = 0.6 \times 0.9 = 0.540, \qquad \psi_1(S) = 0$$
$$\delta_1(\mathrm{R}) = \pi_R \cdot B_{R,0} = 0.4 \times 0.2 = 0.080, \qquad \psi_1(\mathrm{R}) = 0$$
Paso 2 — Recursión ($O_2 = 1$):
Para el estado $S$ en $t=2$:
$$\delta_2(S) = \max(\delta_1(S) \cdot A_{SS}, \delta_1(\mathrm{R}) \cdot A_{RS}) \cdot B_{S,1}$$ $$= \max(0.540 \times 0.7, 0.080 \times 0.4) \times 0.1 = \max(0.378, 0.032) \times 0.1 = 0.0378$$ $$\psi_2(S) = \arg\max(0.378, 0.032) = S \text{ (índice 0)}$$
Para el estado $R$ en $t=2$:
$$\delta_2(\mathrm{R}) = \max(\delta_1(S) \cdot A_{SR}, \delta_1(\mathrm{R}) \cdot A_{RR}) \cdot B_{R,1}$$ $$= \max(0.540 \times 0.3, 0.080 \times 0.6) \times 0.8 = \max(0.162, 0.048) \times 0.8 = 0.1296$$ $$\psi_2(\mathrm{R}) = \arg\max(0.162, 0.048) = S \text{ (índice 0)}$$
Intuición: en $t=2$, el mejor camino a ambos estados pasa por $S$ en $t=1$ (porque $\delta_1(S)$ es mucho mayor que $\delta_1(\mathrm{R})$).
Paso 3 — Recursión ($O_3 = 1$):
Para el estado $S$ en $t=3$:
$$\delta_3(S) = \max(\delta_2(S) \cdot A_{SS}, \delta_2(\mathrm{R}) \cdot A_{RS}) \cdot B_{S,1}$$ $$= \max(0.0378 \times 0.7, 0.1296 \times 0.4) \times 0.1 = \max(0.02646, 0.05184) \times 0.1 = 0.005184$$ $$\psi_3(S) = \arg\max(0.02646, 0.05184) = R \text{ (índice 1)}$$
Para el estado $R$ en $t=3$:
$$\delta_3(\mathrm{R}) = \max(\delta_2(S) \cdot A_{SR}, \delta_2(\mathrm{R}) \cdot A_{RR}) \cdot B_{R,1}$$ $$= \max(0.0378 \times 0.3, 0.1296 \times 0.6) \times 0.8 = \max(0.01134, 0.07776) \times 0.8 = 0.06221$$ $$\psi_3(\mathrm{R}) = \arg\max(0.01134, 0.07776) = R \text{ (índice 1)}$$
Tabla resumen de $\delta$ y $\psi$:
| $t$ | $O_t$ | $\delta_t(S)$ | $\psi_t(S)$ | $\delta_t(\mathrm{R})$ | $\psi_t(\mathrm{R})$ |
|---|---|---|---|---|---|
| 1 | 0 | 0.54000 | — | 0.08000 | — |
| 2 | 1 | 0.03780 | S | 0.12960 | S |
| 3 | 1 | 0.00518 | R | 0.06221 | R |
Backtracking:
- Mejor estado en $t=3$: $q_3^∗ = \arg\max(\delta_3(S), \delta_3(\mathrm{R})) = \arg\max(0.00518, 0.06221) = R$
- $q_2^∗ = \psi_3(\mathrm{R}) = R$
- $q_1^∗ = \psi_2(\mathrm{R}) = S$
Secuencia óptima: $S \to R \to R$
Interpretación: el día sin paraguas fue soleado (lógico: B(S,0)=0.9), y los dos días con paraguas fueron lluviosos (lógico: B(R,1)=0.8). La cadena de Markov “prefiere” mantenerse en el mismo estado (A_SS=0.7, A_RR=0.6), lo que hace que S→R→R sea más probable que S→S→R o cualquier otra variación.
6. Aplicación real: etiquetado gramatical (POS tagging)
El etiquetado gramatical (POS tagging) consiste en asignar a cada palabra de una oración su categoría gramatical: determinante, nombre, verbo, etc. Es un problema de HMM natural: los estados ocultos son las etiquetas gramaticales y las observaciones son las palabras.
La dificultad está en la ambigüedad léxica: “fans” puede ser nombre (los fans) o verbo (avienta aire); “watch” puede ser nombre (un reloj) o verbo (observar); “race” puede ser nombre (la carrera) o verbo (competir). Elegir la etiqueta correcta requiere contexto — exactamente lo que el modelo de transición captura.
Parte 1: El modelo y el fallo del enfoque greedy
Estados ocultos ($N = 3$):
| Estado | Símbolo | Categoría |
|---|---|---|
| Determinante | D | “the”, “a”, … |
| Nombre | N | “fans”, “race”, … |
| Verbo | V | “watch” (verbo), “fans” (verbo), … |
Secuencia de palabras ($T = 5$):
$$O = (\text{the},\ \text{fans},\ \text{watch},\ \text{the},\ \text{race})$$
Distribución inicial $\pi$:
$$\pi_D = 0.8, \qquad \pi_N = 0.1, \qquad \pi_V = 0.1$$
Matriz de transición $A$ (fila = estado actual; columnas = D, N, V):
$$A = \begin{pmatrix} 0.0 & 0.9 & 0.1 \\ 0.0 & 0.5 & 0.5 \\ 0.3 & 0.5 & 0.2 \end{pmatrix} \qquad \begin{array}{l} \text{fila D: } A_{DD}=0,\ A_{DN}=0.9,\ A_{DV}=0.1 \\ \text{fila N: } A_{ND}=0,\ A_{NN}=0.5,\ A_{NV}=0.5 \\ \text{fila V: } A_{VD}=0.3,\ A_{VN}=0.5,\ A_{VV}=0.2 \end{array}$$
Nota importante: $A_{DD} = 0$ y $A_{ND} = 0$. Un determinante nunca sigue directamente a otro, y un nombre nunca precede directamente a un determinante en este modelo. Esto tendrá consecuencias decisivas en el trellis.
Matriz de emisión $B$ (valores para las palabras de la oración):
| “the” | “fans” | “watch” | “race” | |
|---|---|---|---|---|
| D | 0.20 | 0.00 | 0.00 | 0.00 |
| N | 0.00 | 0.10 | 0.30 | 0.10 |
| V | 0.00 | 0.20 | 0.25 | 0.30 |
Nota clave: $B_{N,\text{the}} = B_{V,\text{the}} = 0$ — solo los determinantes pueden emitir “the”. Cualquier estado N o V en el instante de “the” tendrá $\delta = 0$ automáticamente.
El fallo del enfoque greedy
Un enfoque ingenuo elegiría, para cada palabra, el estado con mayor emisión $B_{j,\text{word}}$, ignorando las transiciones. Para las palabras ambiguas:
| Palabra | $B_{N,\text{word}}$ | $B_{V,\text{word}}$ | Elección greedy |
|---|---|---|---|
| “fans” | 0.10 | 0.20 | V (0.20 > 0.10) |
| “watch” | 0.30 | 0.25 | N (0.30 > 0.25) |
| “race” | 0.10 | 0.30 | V (0.30 > 0.10) |
“the” solo puede ser D (emisión cero en N y V). El resultado greedy sería:
$$D \to V \to N \to D \to V$$
Pero esta secuencia es imposible según el modelo: $A_{ND} = 0$, es decir, la transición de N (“watch”) a D (“the”) tiene probabilidad cero. El enfoque greedy, al ignorar las transiciones, produjo una secuencia incongruente con el modelo.
Viterbi maximiza la probabilidad conjunta de toda la secuencia y evitará este error.
Parte 2: Traza Viterbi paso a paso
$t = 1$ — “the”
$$\delta_1(D) = \pi_D \cdot B_{D,\text{the}} = 0.8 \times 0.2 = 0.16, \qquad \psi_1(D) = \text{—}$$
$$\delta_1(N) = \pi_N \cdot B_{N,\text{the}} = 0.1 \times 0 = 0 \quad (\text{nodo muerto})$$
$$\delta_1(V) = \pi_V \cdot B_{V,\text{the}} = 0.1 \times 0 = 0 \quad (\text{nodo muerto})$$
Solo D sobrevive en $t=1$. Las dos ramas N y V mueren por emisión cero.
$t = 2$ — “fans”
$$\delta_2(N) = \max[\delta_1(D) \cdot A_{DN},\ \delta_1(N) \cdot A_{NN},\ \delta_1(V) \cdot A_{VN}] \cdot B_{N,\text{fans}}$$ $$= \max[0.16 \times 0.9,\ 0,\ 0] \times 0.1 = 0.144 \times 0.1 = 0.0144, \qquad \psi_2(N) = D$$
$$\delta_2(V) = \max[\delta_1(D) \cdot A_{DV},\ \delta_1(N) \cdot A_{NV},\ \delta_1(V) \cdot A_{VV}] \cdot B_{V,\text{fans}}$$ $$= \max[0.16 \times 0.1,\ 0,\ 0] \times 0.2 = 0.016 \times 0.2 = 0.0032, \qquad \psi_2(V) = D$$
$$\delta_2(D) = \max[0,\ 0,\ 0] \times B_{D,\text{fans}} = 0 \quad (\text{nodo muerto})$$
Ambas ramas N y V sobreviven. El único origen posible es D (el único nodo vivo en $t=1$).
$t = 3$ — “watch” — Poda tipo 1: regla del máximo
Dos caminos pueden llegar a N en $t=3$ (desde N o desde V en $t=2$). Viterbi compara y descarta el peor:
$$\text{vía N: } \delta_2(N) \cdot A_{NN} = 0.0144 \times 0.5 = 0.0072$$ $$\text{vía V: } \delta_2(V) \cdot A_{VN} = 0.0032 \times 0.5 = 0.0016$$ $$\max(0.0072,\ 0.0016) = 0.0072 \Rightarrow \delta_3(N) = 0.0072 \times 0.3 = 0.00216, \qquad \psi_3(N) = N$$
Del mismo modo para V en $t=3$:
$$\text{vía N: } \delta_2(N) \cdot A_{NV} = 0.0144 \times 0.5 = 0.0072$$ $$\text{vía V: } \delta_2(V) \cdot A_{VV} = 0.0032 \times 0.2 = 0.00064$$ $$\max(0.0072,\ 0.00064) = 0.0072 \Rightarrow \delta_3(V) = 0.0072 \times 0.25 = 0.00180, \qquad \psi_3(V) = N$$
Poda tipo 1 — regla del máximo: Viterbi descarta todos los caminos al mismo nodo salvo el de mayor $\delta_{t-1}(i) \cdot A_{ij}$. En ambos nodos (N y V en $t=3$), el camino vía N domina al vía V (0.0072 > 0.0016 y 0.0072 > 0.00064). Solo el camino ganador se propaga.
$$\delta_3(D) = 0 \quad (B_{D,\text{watch}} = 0,\ \text{D muerto})$$
$t = 4$ — “the” — Poda tipo 2: transición nula
$B_{N,\text{the}} = B_{V,\text{the}} = 0$, por lo que $\delta_4(N) = \delta_4(V) = 0$ independientemente. Solo D puede sobrevivir.
Para D en $t=4$, los caminos posibles son:
$$\text{vía N: } \delta_3(N) \cdot A_{ND} = 0.00216 \times 0 = 0 \quad (A_{ND} = 0,\ \text{eliminado})$$ $$\text{vía V: } \delta_3(V) \cdot A_{VD} = 0.00180 \times 0.3 = 0.000540$$ $$\delta_4(D) = 0.000540 \times B_{D,\text{the}} = 0.000540 \times 0.2 = 0.000108, \qquad \psi_4(D) = V$$
Poda tipo 2 — transición nula: $A_{ND} = 0$ elimina el camino desde N sin importar cuánta probabilidad acumuló $\delta_3(N)$. Solo el camino vía V sobrevive para llegar a D.
$t = 5$ — “race” — Terminación
$$\delta_5(N) = \max[\delta_4(D) \cdot A_{DN},\ 0,\ 0] \cdot B_{N,\text{race}} = (0.000108 \times 0.9) \times 0.1 = 9.72 \times 10^{-6}, \qquad \psi_5(N) = D$$
$$\delta_5(V) = \max[\delta_4(D) \cdot A_{DV},\ 0,\ 0] \cdot B_{V,\text{race}} = (0.000108 \times 0.1) \times 0.3 = 3.24 \times 10^{-6}, \qquad \psi_5(V) = D$$
$$\delta_5(D) = 0 \quad (B_{D,\text{race}} = 0,\ \text{D muerto})$$
Mejor estado en $t=5$: N ($9.72 \times 10^{-6} > 3.24 \times 10^{-6}$).
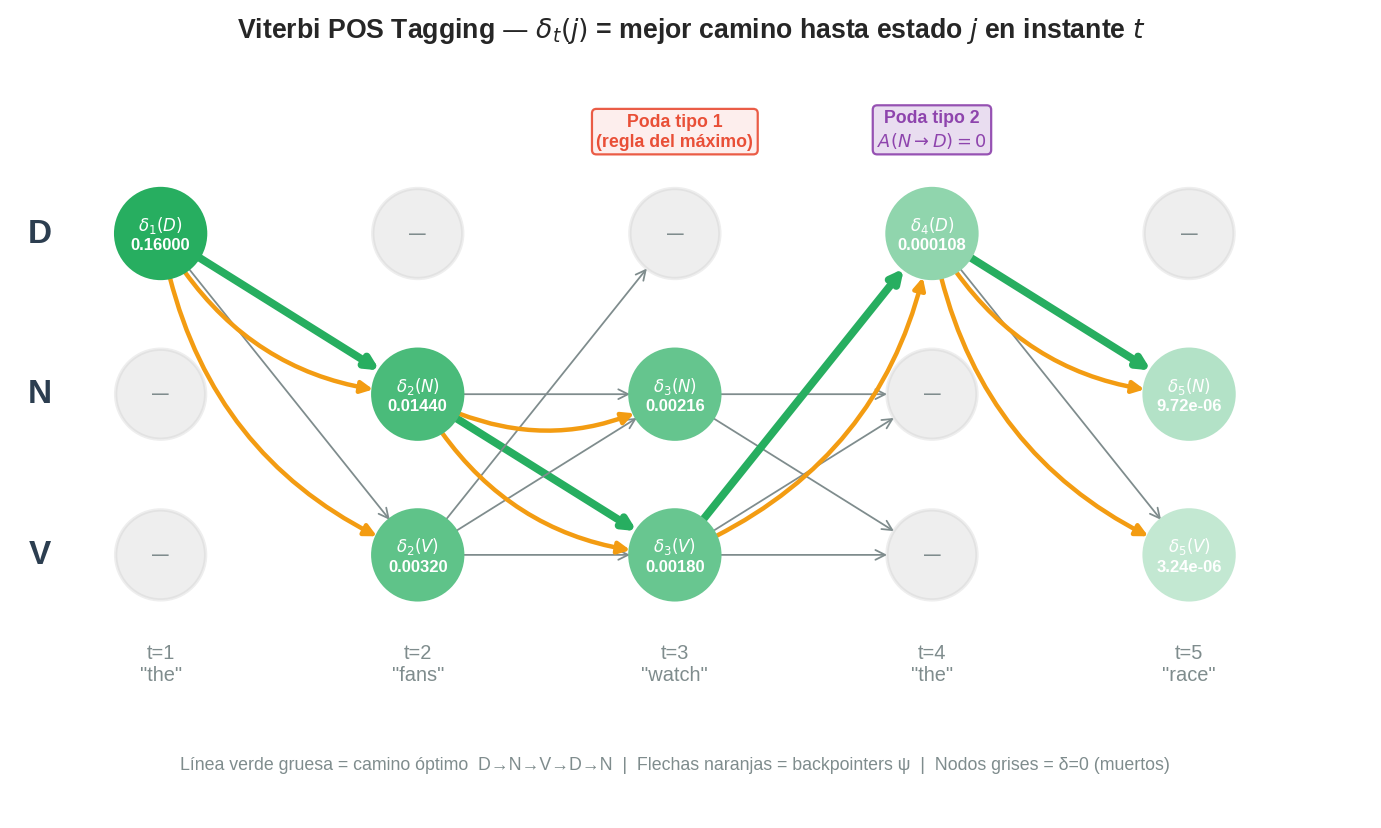
Tabla resumen del trellis
t=1 "the" t=2 "fans" t=3 "watch" t=4 "the" t=5 "race"
────────┬────────────┬────────────┬────────────┬────────────┬────────────
D │ 0.16000 │ — │ — │ 1.08e-4 │ —
│ ψ=— │ │ │ ψ=V │
────────┼────────────┼────────────┼────────────┼────────────┼────────────
N │ — │ 0.01440 │ 0.00216 │ — │ 9.72e-6 ★
│ │ ψ=D │ ψ=N │ │ ψ=D
────────┼────────────┼────────────┼────────────┼────────────┼────────────
V │ — │ 0.00320 │ 0.00180 │ — │ 3.24e-6
│ │ ψ=D │ ψ=N │ │ ψ=D
Camino óptimo: $D \to N \to V \to D \to N$.
Backtracking: de $t=5$ a $t=1$
Seguimos los backpointers desde el mejor estado final hacia el inicio:
- $t=5$: $q_5^∗ = N$ (mayor $\delta_5$). Seguimos $\psi_5(N) = D \Rightarrow q_4^∗ = D$.
- $t=4$: $q_4^∗ = D$. Seguimos $\psi_4(D) = V \Rightarrow q_3^∗ = V$.
- $t=3$: $q_3^∗ = V$. Seguimos $\psi_3(V) = N \Rightarrow q_2^∗ = N$.
- $t=2$: $q_2^∗ = N$. Seguimos $\psi_2(N) = D \Rightarrow q_1^∗ = D$.
- $t=1$: $q_1^∗ = D$. Inicio de la secuencia.
Secuencia óptima: $D \to N \to V \to D \to N$
| Palabra | “the” | “fans” | “watch” | “the” | “race” |
|---|---|---|---|---|---|
| Etiqueta | D | N | V | D | N |
Viterbi encontró que “fans” es nombre y “watch” es verbo — la interpretación correcta de “the fans watch the race” (los fans miran la carrera). El modelo de transición resolvió la ambigüedad que el enfoque greedy no pudo manejar: la clave fue $A_{ND} = 0$, que bloqueó la ruta imposible N→D y forzó al camino óptimo a pasar por V en $t=3$.
7. Pseudocódigo
función VITERBI(O, π, A, B):
T ← longitud(O)
N ← número de estados
[P1] Inicialización:
para i = 1 hasta N:
δ[1][i] ← π[i] × B[i][O[1]]
ψ[1][i] ← 0
[P2] Recursión:
para t = 2 hasta T:
para j = 1 hasta N:
mejor_val ← -∞
mejor_i ← 0
para i = 1 hasta N:
val ← δ[t-1][i] × A[i][j]
si val > mejor_val:
mejor_val ← val
mejor_i ← i
δ[t][j] ← mejor_val × B[j][O[t]]
ψ[t][j] ← mejor_i
[P3] Terminación:
q*[T] ← argmax_i δ[T][i]
[P4] Backtracking:
para t = T-1 hasta 1:
q*[t] ← ψ[t+1][ q*[t+1] ]
retornar q*, δ, ψ
8. Complejidad
Igual que Forward: $O(N^2 T)$ en tiempo, $O(NT)$ en espacio (más $O(NT)$ para los backpointers $\psi$). El cambio de suma a máximo no altera la complejidad asintótica — solo la naturaleza de la operación en el bucle interno.
9. Viterbi vs Forward: una última comparación
Una confusión frecuente: el estado de máxima probabilidad marginal $\arg\max_i \gamma_t(i)$ (donde $\gamma_t(i) = P(q_t=i \mid O, \lambda)$ es la posterior calculada en la sección 20.3) no es necesariamente el mismo que el estado de la secuencia de Viterbi $q_t^∗$.
¿Por qué? Porque $\gamma_t(i)$ maximiza cada instante de forma independiente, sin garantizar que la secuencia completa sea coherente (por ejemplo, podría resultar una secuencia donde la transición de $q_t^∗$ a $q_{t+1}^∗$ tiene probabilidad cero).
Viterbi maximiza la probabilidad de la secuencia completa conjuntamente, lo que garantiza una trayectoria coherente con las probabilidades de transición del modelo.
Usa $\gamma$ (Forward-Backward) cuando quieras el estado más probable en cada instante por separado. Usa Viterbi cuando quieras la secuencia más probable como un todo.