| Notebook | Colab |
|---|---|
| Notebook 02 — Ergodicidad |
Teorema Ergódico
“A single trajectory, observed long enough, tells you everything about the whole system.”
Este es el resultado central del módulo — el teorema que vincula todo lo anterior. En la sección 01 conocimos la disputa entre Markov y Nekrasov. En la sección 02 definimos cadenas de Markov y simulamos trayectorias. En la sección 03 identificamos las propiedades (irreducibilidad, aperiodicidad) y calculamos la distribución estacionaria $\pi$. Ahora respondemos la pregunta que motivó todo desde el principio.
1. La pregunta que empezó todo
Recordemos la disputa Markov–Nekrasov de la sección 01. Nekrasov afirmó: la Ley de los Grandes Números requiere independencia. Por lo tanto, si las estadísticas humanas convergen a promedios estables, las acciones humanas deben ser independientes — y eso prueba el libre albedrío divino.
Markov dijo: no. La independencia es suficiente, pero no necesaria. Y se propuso demostrarlo construyendo secuencias dependientes que aun así obedecieran la LLN.
La pregunta concreta es esta:
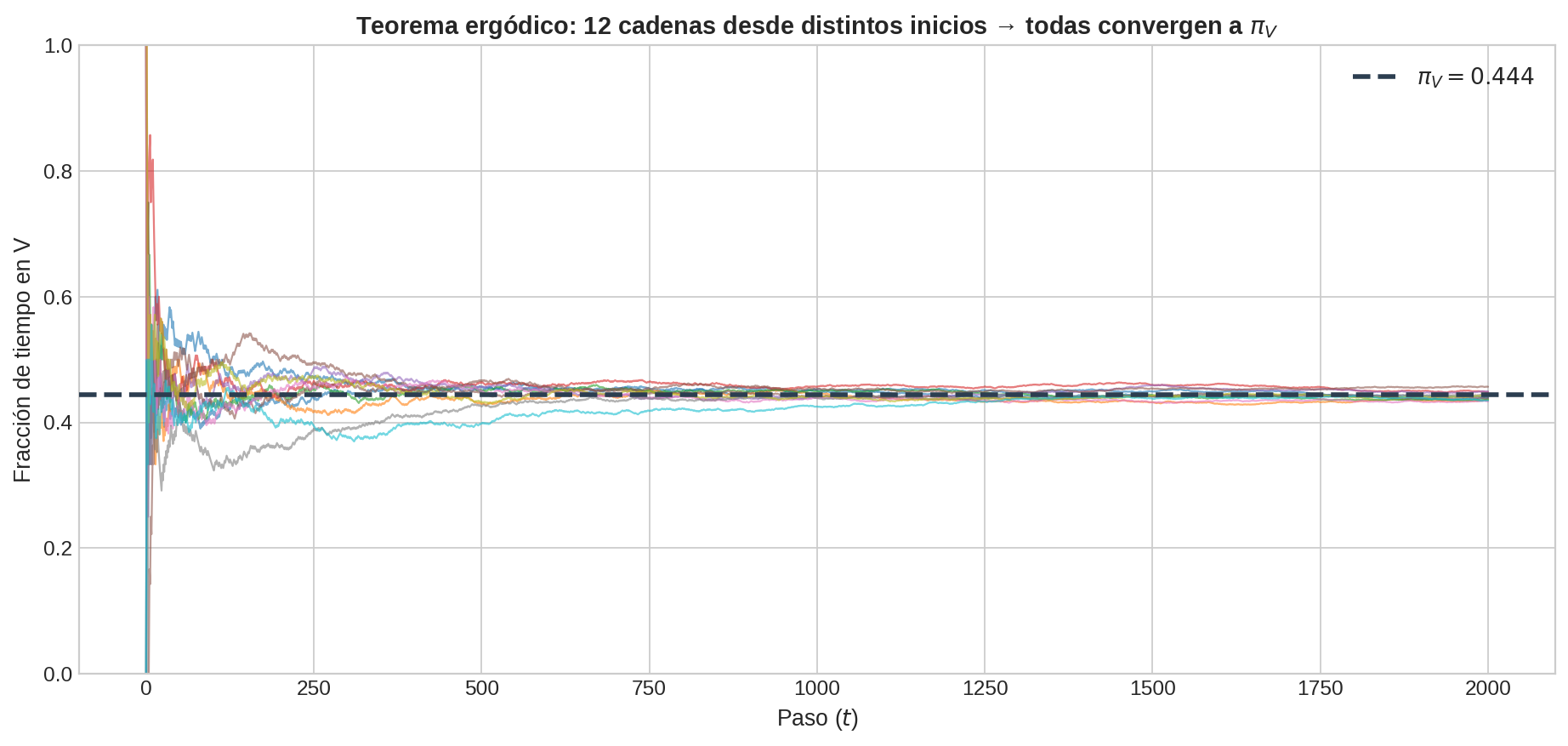
Si observo una sola cadena de Markov durante $T$ pasos, ¿converge la fracción de tiempo que la cadena pasa en el estado $j$ al valor $\pi_j$?
En otras palabras: ¿puedo reemplazar el muestreo independiente por una única trayectoria larga de una cadena de Markov y aun así obtener promedios correctos?
El teorema ergódico dice que sí. Es la prueba definitiva de Markov.
2. Enunciado en lenguaje natural
Para una cadena de Markov finita que sea irreducible y aperiódica, con distribución estacionaria $\pi$:
-
Convergencia de la distribución inicial. No importa dónde empieces — después de suficientes pasos, la distribución sobre los estados se acerca a $\pi$. El estado inicial se olvida.
-
Convergencia del promedio temporal. La fracción de tiempo que la cadena pasa en el estado $j$ converge a $\pi_j$. Si $\pi_j = 0.444$, entonces a largo plazo la cadena visita el estado $j$ aproximadamente el 44.4% del tiempo.
-
Promedios de funciones. Para cualquier función $f$ definida sobre los estados, el promedio temporal converge al valor esperado bajo $\pi$:
$$\frac{1}{T}\sum_{t=0}^{T-1} f(X_t) ;\xrightarrow{T \to \infty}; \mathbb E_\pi[f] = \sum_{j \in S} \pi_j , f(j)$$
El tercer punto es el más poderoso: dice que podemos calcular valores esperados ejecutando una sola cadena. No necesitamos muestras independientes. No necesitamos reiniciar. Una trayectoria suficientemente larga basta.
3. Enunciado formal
Sea ${X_0, X_1, \ldots}$ una cadena de Markov irreducible, aperiódica y finita con distribución estacionaria $\pi$. Entonces, para todo estado $j \in S$ y para cualquier estado inicial $X_0$:
$$\frac{1}{T} \sum_{t=0}^{T-1} \mathbf{1}[X_t = j] \xrightarrow{T \to \infty} \pi_j \quad \text{con probabilidad 1}$$
Más generalmente: para cualquier función $f : S \to \mathbb{R}$,
$$\frac{1}{T} \sum_{t=0}^{T-1} f(X_t) \xrightarrow{T \to \infty} \sum_{j \in S} \pi_j , f(j) = \mathbb E_\pi[f]$$
Comparación con la LLN clásica
| LLN clásica (Módulo 5) | Teorema Ergódico (Módulo 19) | |
|---|---|---|
| Muestras | $X_1, \ldots, X_n$ i.i.d. | $X_0, X_1, \ldots, X_{T-1}$ dependientes |
| Convergencia | $\frac{1}{n}\sum f(X_i) \to \mathbb{E}[f]$ | $\frac{1}{T}\sum f(X_t) \to \mathbb E_\pi[f]$ |
| Requisito | Independencia | Ergodicidad (irreducible + aperiódica) |
| Velocidad | $O(1/\sqrt{n})$ | $O(1/\sqrt{T})$ (más lenta por autocorrelación) |
La estructura es idéntica: un promedio empírico converge a un valor teórico. La diferencia es que en la LLN clásica las muestras son independientes, mientras que en el teorema ergódico las muestras forman una cadena con dependencia explícita. La convergencia es más lenta — la autocorrelación entre pasos consecutivos reduce la “información efectiva” de cada muestra — pero la convergencia ocurre.
Nota histórica. El teorema ergódico fue demostrado por John von Neumann en 1931 (versión de convergencia en $L^2$) y por George Birkhoff poco después (versión con probabilidad 1, que es la que aparece aquí). En cadenas de Markov finitas ambas versiones son equivalentes. Von Neumann consideraba este resultado uno de los teoremas más bellos de las matemáticas: unifica análisis, probabilidad y dinámica en un solo enunciado, y lo hace sin exigir independencia.
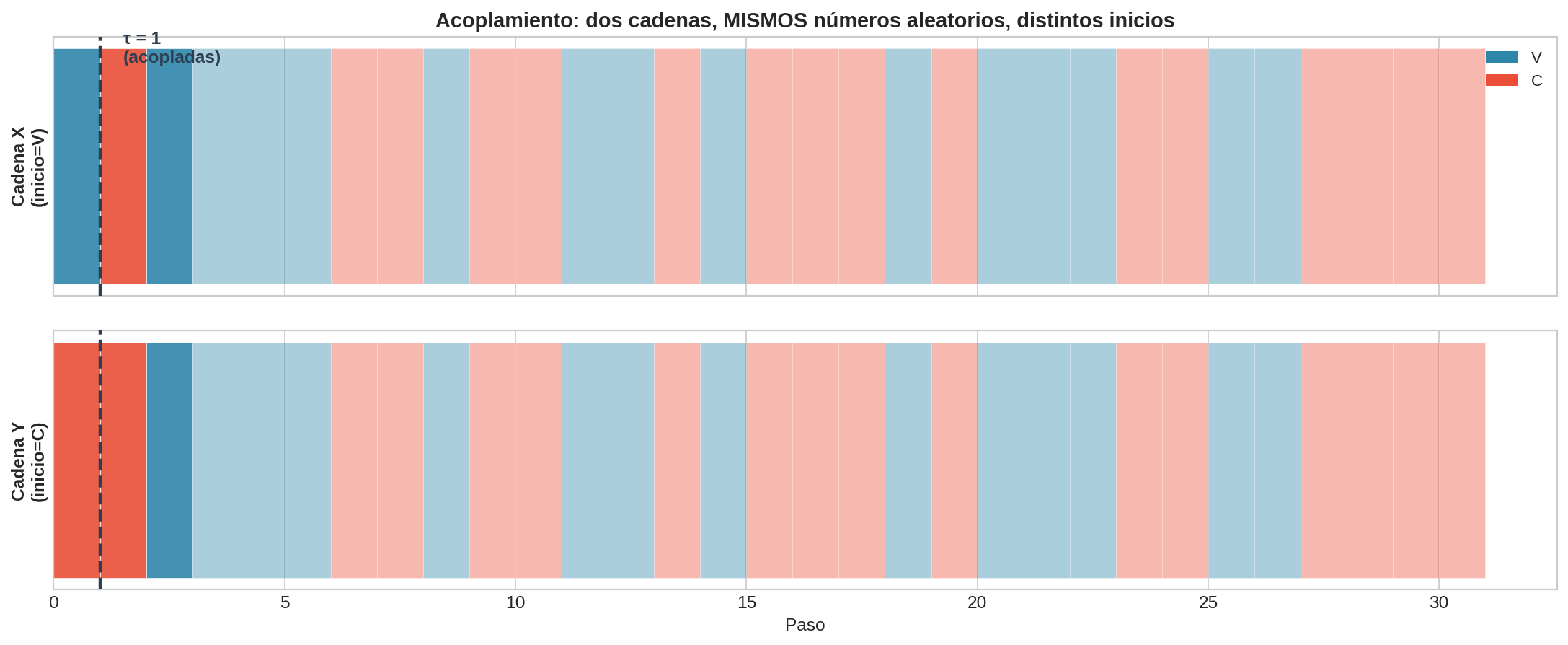
4. Prueba intuitiva: el argumento de acoplamiento (cadena de 2 estados)
Esta es la idea central de la demostración, presentada sin formalismos. Usamos la cadena V/C como ejemplo concreto.
La construcción
Imagina dos copias de la cadena V/C. Ambas usan la misma matriz de transición $\mathbf{P}$. En cada paso, ambas usan el mismo número aleatorio $u \sim \text{Uniforme}(0, 1)$. La única diferencia: la cadena $X$ empieza en $V$ y la cadena $Y$ empieza en $C$.
Recordemos las reglas de transición:
- Desde $V$: si $u < 0.35$ queda en $V$; si $u \geq 0.35$ pasa a $C$.
- Desde $C$: si $u < 0.52$ pasa a $V$; si $u \geq 0.52$ queda en $C$.
Traza guiada
| Paso | $u$ | Cadena X (inicio V) | Cadena Y (inicio C) | ¿Iguales? | ||
|---|---|---|---|---|---|---|
| 0 | — | V | C | No | ||
| 1 | 0.71 | V: 0.71 $\geq$ 0.35 | C | C: 0.71 $\geq$ 0.52 | C | ¡Sí! |
| 2 | 0.15 | C: 0.15 < 0.52 | V | C: 0.15 < 0.52 | V | Sí |
| 3 | 0.42 | V: 0.42 $\geq$ 0.35 | C | V: 0.42 $\geq$ 0.35 | C | Sí |
| 4 | 0.88 | C: 0.88 $\geq$ 0.52 | C | C: 0.88 $\geq$ 0.52 | C | Sí $\forall$ |
Qué pasó aquí
- Paso 0: Las cadenas empiezan en estados diferentes — $X_0 = V$, $Y_0 = C$.
- Paso 1: Ambas cadenas reciben el mismo $u = 0.71$. La cadena $X$ (en $V$) evalúa: $0.71 \geq 0.35$, así que pasa a $C$. La cadena $Y$ (en $C$) evalúa: $0.71 \geq 0.52$, así que se queda en $C$. Ambas están ahora en $C$. Este es el tiempo de acoplamiento $\tau = 1$.
- Paso 2 en adelante: Ambas cadenas están en el mismo estado y reciben el mismo número aleatorio. Aplican la misma fila de $\mathbf{P}$ con el mismo $u$, así que producen el mismo resultado. Las trayectorias son idénticas para siempre.
- El estado inicial ya no importa.
Generalización
Esto no siempre ocurre en el paso 1. A veces las cadenas tardan más en acoplarse — quizás $u$ cae en una región donde los umbrales de $V$ y $C$ difieren y las cadenas van a estados distintos. Pero el mecanismo clave es: cuando ambas cadenas llegan al mismo estado en el mismo paso, a partir de ese momento reciben el mismo $u$ y consultan la misma fila de $\mathbf{P}$, así que transicionan de forma idéntica para siempre. Como la cadena es irreducible, en cada paso hay una probabilidad positiva $\epsilon > 0$ de que esto ocurra.
¿Cuál es la probabilidad de nunca acoplarse? Si la probabilidad de acoplarse en un paso es al menos $\epsilon > 0$, entonces la probabilidad de no acoplarse en $n$ pasos es a lo más $(1 - \epsilon)^n$. Conforme $n \to \infty$, esto converge a cero. Es un argumento geométrico: la probabilidad de fallar infinitas veces es cero.
El acoplamiento debe ocurrir eventualmente.
Después del acoplamiento, $X_t = Y_t$ para todo $t$ futuro. Como $Y$ pudo haber empezado en cualquier estado y eventualmente coincide con $X$, el estado inicial es irrelevante para el comportamiento a largo plazo. Ese comportamiento a largo plazo es la distribución estacionaria $\pi$.
Esta es la razón por la que $\mathbf{P}^n$ converge a una matriz donde todas las filas son idénticas: cada estado inicial lleva al mismo comportamiento a largo plazo. Vimos esta convergencia numéricamente en la sección 02 (tabla de potencias de $\mathbf{P}$ para la cadena V/C). Ahora sabemos por qué ocurre.
5. La vindicación de Markov
Esto es exactamente lo que Markov demostró contra Nekrasov.
La LLN clásica dice: el promedio de variables independientes converge al valor esperado. Nekrasov afirmó que sin independencia la ley no aplica — y construyó sobre esa afirmación un argumento teológico sobre el libre albedrío y la existencia de Dios.
El teorema ergódico dice: no. Incluso para secuencias dependientes — cadenas de Markov — el promedio temporal converge al promedio estacionario. La dependencia no rompe la convergencia; solo cambia la velocidad.
Markov tenía razón. La independencia es suficiente para la LLN, pero no necesaria. La ergodicidad es suficiente. Y las cadenas de Markov — secuencias con dependencia explícita — son ergódicas bajo las condiciones que Markov identificó: irreducibilidad y aperiodicidad.
La disputa quedó resuelta con un teorema. Nekrasov necesitaba que la independencia fuera necesaria para sostener su argumento. No lo es. El edificio teológico se derrumbó, y en su lugar quedó una de las herramientas matemáticas más poderosas del siglo XX.
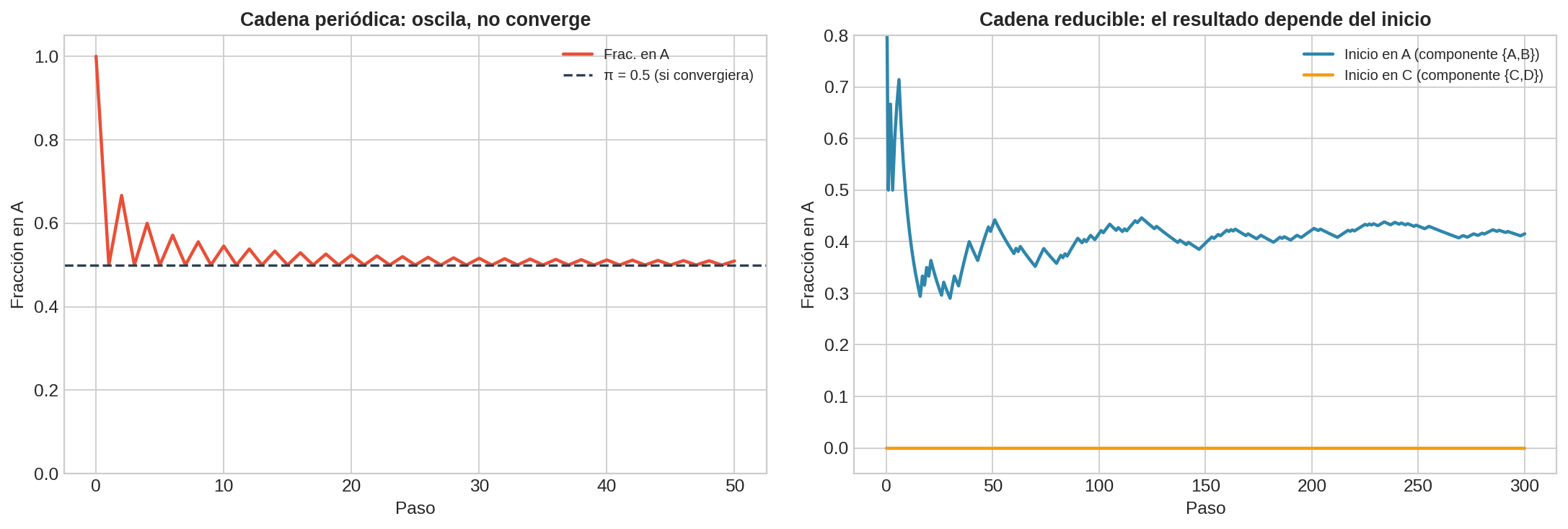
6. Cuándo se rompe la ergodicidad
El teorema ergódico requiere que la cadena sea irreducible y aperiódica. ¿Qué pasa cuando alguna de estas condiciones falla?
Cadena periódica (período 2)
Consideremos una cadena con dos estados ${A, B}$ y matriz de transición:
| a $A$ | a $B$ | |
|---|---|---|
| desde $A$ | 0 | 1 |
| desde $B$ | 1 | 0 |
La cadena alterna determinísticamente: $A \to B \to A \to B \to \cdots$
- $\mathbf{P}^n$ oscila: en tiempos pares la cadena está en el estado inicial, en tiempos impares en el otro.
- $P(X_t = A)$ alterna entre 0 y 1 en vez de converger.
- El promedio temporal $\frac{1}{T}\sum \mathbf{1}[X_t = A]$ sí converge a 0.5 — pero la distribución no se estabiliza. La cadena nunca “olvida” dónde empezó; solo que el promedio temporal promedia las oscilaciones.
- $\mathbf{P}^n$ no converge a una matriz con filas idénticas — oscila entre $\mathbf{I}$ y $\mathbf{P}$.
La periodicidad impide la convergencia de la distribución, aunque no destruye completamente los promedios temporales.
Cadena reducible
Consideremos una cadena con cuatro estados ${A, B, C, D}$ donde ${A, B}$ y ${C, D}$ forman dos componentes desconectadas:
| a $A$ | a $B$ | a $C$ | a $D$ | |
|---|---|---|---|---|
| desde $A$ | 0.7 | 0.3 | 0 | 0 |
| desde $B$ | 0.4 | 0.6 | 0 | 0 |
| desde $C$ | 0 | 0 | 0.5 | 0.5 |
| desde $D$ | 0 | 0 | 0.8 | 0.2 |
- Si empiezas en ${A, B}$, te quedas en ${A, B}$ para siempre.
- Si empiezas en ${C, D}$, te quedas en ${C, D}$ para siempre.
- Diferentes componentes iniciales producen diferentes comportamientos a largo plazo.
- No existe una distribución estacionaria única — cada componente tiene la suya.
La reducibilidad hace que el estado inicial sí importa para siempre. El argumento de acoplamiento falla porque las dos copias de la cadena nunca pueden encontrarse si empiezan en componentes diferentes.
Resumen
| Condición | ¿Qué pasa si falla? | ¿Converge $\mathbf{P}^n$? | ¿Converge el promedio temporal? |
|---|---|---|---|
| Irreducibilidad | La cadena queda atrapada en componentes | No (depende del inicio) | Solo dentro de cada componente |
| Aperiodicidad | La cadena oscila entre subconjuntos | No (oscila) | Sí (pero la distribución no se estabiliza) |
| Ambas | Ergodicidad plena | Sí | Sí |
Ambas condiciones — irreducible y aperiódica — son necesarias para la convergencia completa.
7. Velocidad de convergencia: tiempo de mezcla
Sabemos que $\mathbf{P}^n$ converge a $\pi$. Pero ¿qué tan rápido? La respuesta involucra el segundo eigenvalor más grande de $\mathbf{P}$.
La matriz $\mathbf{P}$ tiene eigenvalores $\lambda_1 = 1 \geq |\lambda_2| \geq \cdots \geq |\lambda_k|$. El eigenvalor dominante $\lambda_1 = 1$ corresponde a la distribución estacionaria. La velocidad de convergencia está controlada por $|\lambda_2|$:
$$|\mathbf{P}^n[i, \cdot] - \pi| \leq C \cdot |\lambda_2|^n$$
- Si $|\lambda_2|$ es pequeño (cercano a 0): mezcla rápida. La cadena olvida su estado inicial en pocos pasos.
- Si $|\lambda_2|$ es cercano a 1: mezcla lenta. La cadena tarda muchos pasos en converger.
Ejemplo: cadena V/C
La matriz $\mathbf{P}$ de la cadena V/C tiene eigenvalores $\lambda_1 = 1.0$ y $\lambda_2 = -0.17$ (para una matriz $2 \times 2$, $\lambda_1 + \lambda_2 = \text{traza} = 0.35 + 0.48 = 0.83$, y como $\lambda_1 = 1$, obtenemos $\lambda_2 = 0.83 - 1 = -0.17$). Por lo tanto $|\lambda_2| = 0.17$ — mezcla muy rápida. Después de apenas $\sim$10 pasos la cadena ha olvidado esencialmente su estado inicial. Esto es consistente con lo que vimos en la tabla de potencias de la sección 02: para $n = 8$ las filas ya eran prácticamente idénticas.
Ejemplo: mezcla lenta
Imagina una cadena con dos clusters grandes conectados por un solo enlace débil. La cadena pasa la mayor parte del tiempo dentro de un cluster antes de eventualmente cruzar al otro. En este caso $|\lambda_2|$ está cerca de 1 y la convergencia es lenta — la cadena queda “atrapada” en un cluster durante muchos pasos antes de explorar el otro.
Este fenómeno es crítico en MCMC (sección 06): si la cadena mezcla lentamente, necesitamos muchas más muestras para obtener estimaciones confiables. Diagnosticar y mejorar la velocidad de mezcla es uno de los problemas centrales de la estadística computacional moderna.
En los notebooks mediremos el tiempo de mezcla empíricamente.
← Propiedades · Siguiente: Aplicaciones →