21.2 — La escalera y la ecuación de Bellman
“Tú no descubres la ecuación leyéndola. La descubres llenando la tabla.”
En esta página vas a hacer el trabajo. Al final vas a tener la ecuación de Bellman escrita — no porque yo te la haya dictado, sino porque la vas a haber usado cinco veces antes de que le pongamos nombre.
El problema: una escalera con costos
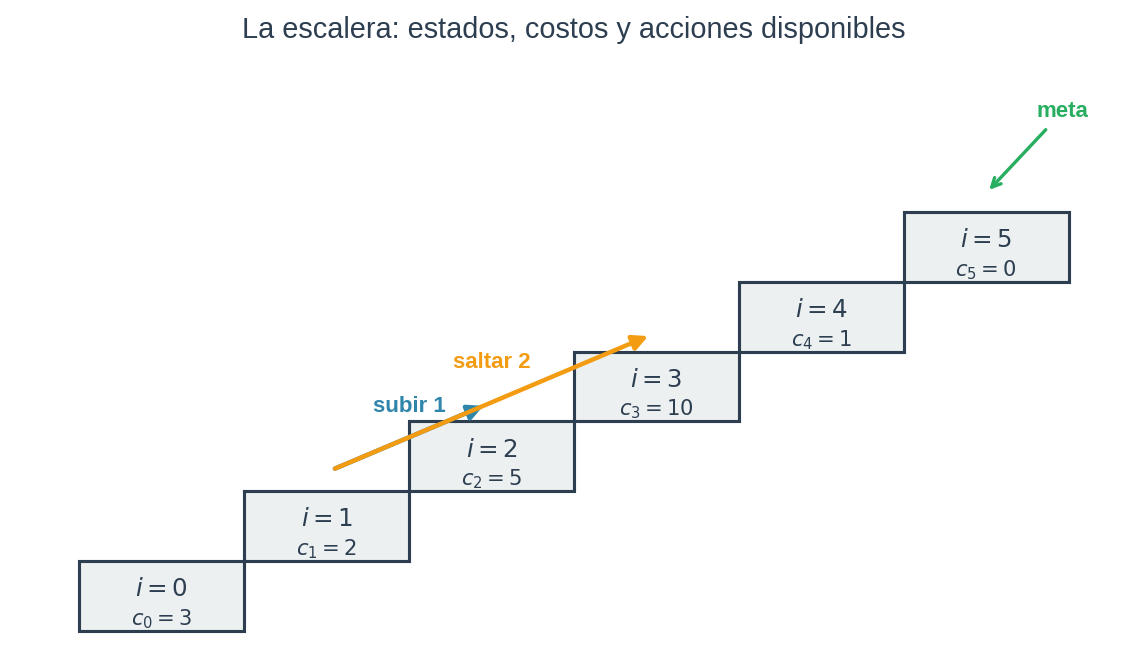
Imagina una escalera de 6 escalones, numerados del 0 al 5. Empiezas en el escalón 0. Tu meta es llegar al escalón 5. En cada turno puedes hacer una de dos cosas:
- Subir 1 — avanzas al escalón siguiente.
- Saltar 2 — avanzas dos escalones.
Cada escalón te cuesta algo en energía (cansancio, tiempo, lo que quieras imaginar). El costo del escalón $i$ es $c_i$. Aquí están los costos de nuestra escalera:
| Escalón $i$ | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| Costo $c_i$ | 3 | 2 | 5 | 10 | 1 | 0 |
El costo total que pagas es la suma de los costos de los escalones donde aterrizas. La pregunta es simple:
¿Cuál es la secuencia de movimientos que minimiza el costo total del escalón 0 al escalón 5?
El intento codicioso — y cómo falla
Antes de pensar en grande, probemos la estrategia codiciosa: en cada paso, elige el escalón siguiente más barato.
- Desde 0: puedes ir a 1 (costo 2) o a 2 (costo 5). Elige 1 (cuesta menos).
- Desde 1: puedes ir a 2 (costo 5) o a 3 (costo 10). Elige 2.
- Desde 2: puedes ir a 3 (costo 10) o a 4 (costo 1). Elige 4 (saltar 2).
- Desde 4: sube 1. Llegas a 5.
Trayectoria codiciosa: 0 → 1 → 2 → 4 → 5. El costo es la suma de los escalones donde aterrizas (no cobramos el 0 porque ahí empezaste): $c_1 + c_2 + c_4 + c_5 = 2 + 5 + 1 + 0 = 8$.
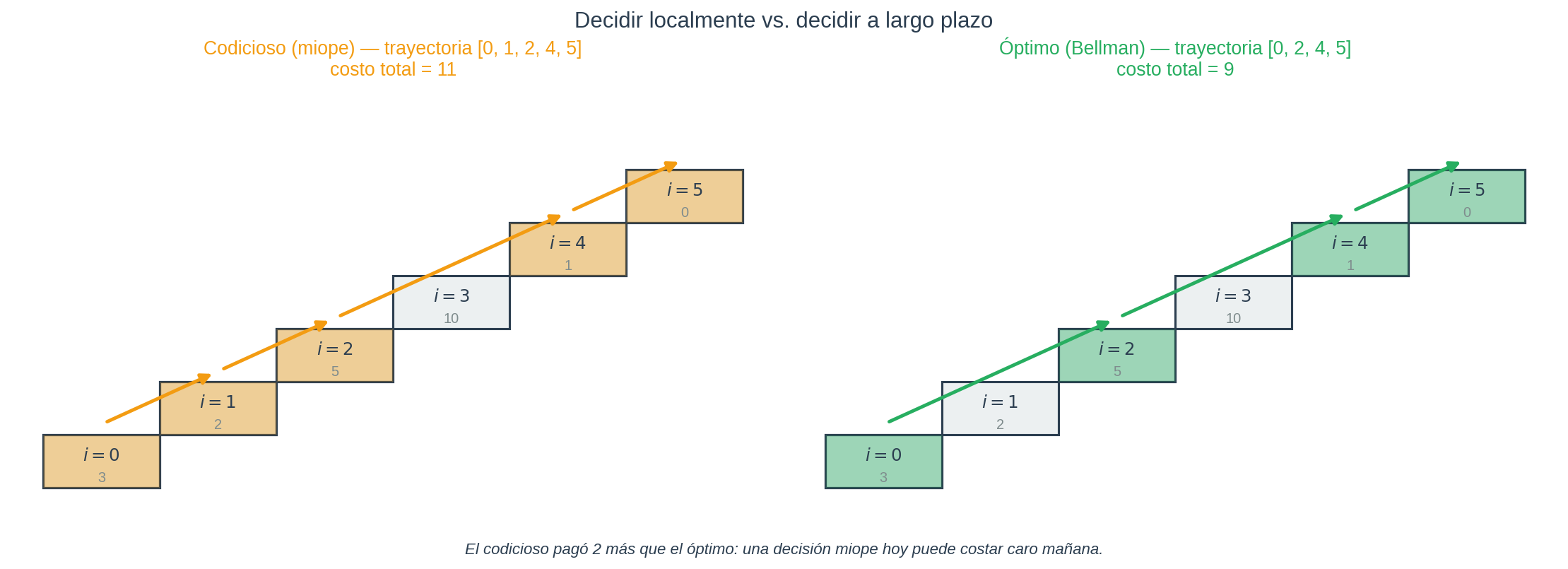
Ahora mira esta otra trayectoria — 0 → 2 → 4 → 5 — con costo $c_2 + c_4 + c_5 = 5 + 1 + 0 = 6$. ¡Más barata!
¿Por qué? Porque pasar por el escalón 1 es inútil: el codicioso paga $c_1 = 2$ por aterrizar ahí, pero luego pasa al escalón 2 — el mismo al que habría llegado saltando directo desde 0. El desvío por 1 no compró nada, solo cobró $c_1 = 2$ de más. El codicioso, midiendo solo el siguiente escalón, no pudo verlo.
Esa es la trampa: una decisión locamente buena puede llevarte a un lugar donde las decisiones siguientes son iguales o peores que si hubieras elegido distinto. No basta comparar escalón contra escalón — hay que pensar en secuencias.
Queremos un método que nunca caiga en este tipo de trampa. Vamos a construirlo.
La idea — pensar desde la meta hacia atrás
El principio de optimalidad nos dice algo muy específico: para saber qué hacer en el escalón 0, primero necesitamos saber qué tan barato es llegar a la meta desde el escalón 1 y desde el escalón 2. Entonces empezamos por la meta y vamos hacia atrás.
Definamos, para cada escalón $i$:
$$V(i) = \text{el costo mínimo total que todavía tienes que pagar para llegar a la meta, si ya estás en } i.$$
Fíjate en el “todavía”: $V(i)$ cuenta los costos futuros — lo que te falta pagar a partir de ahora. El costo de estar en $i$ no se cuenta: o ya lo pagaste al llegar, o si empiezas ahí, no tiene sentido “cobrártelo”.
Tu tarea: llenar la siguiente tabla, de derecha a izquierda.
| Escalón $i$ | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| Costo $c_i$ | 3 | 2 | 5 | 10 | 1 | 0 |
| Valor $V(i)$ | ? | ? | ? | ? | ? | ? |
Vamos a ir paso por paso.
Paso 1 — ¿cuánto cuesta llegar a la meta desde la meta?
Si ya estás en el escalón 5, ya llegaste — no pagas nada más.
$$V(5) = 0.$$
Paso 2 — desde el escalón 4
Desde 4 la única jugada es subir 1 (saltar 2 te sacaría de la escalera). Al tomar esa acción pagas $c_5 = 0$ (el costo de aterrizar en 5) y el resto ya es $V(5) = 0$:
$$V(4) = c_5 + V(5) = 0 + 0 = 0. \quad [\text{acción: subir 1}]$$
Paso 3 — desde el escalón 3
Desde 3 tienes dos opciones. Al tomar una acción pagas el costo del escalón al que aterrizas, más el valor futuro desde ahí:
- Subir 1 (vas a 4): pagas $c_4 + V(4) = 1 + 0 = 1$.
- Saltar 2 (vas a 5): pagas $c_5 + V(5) = 0 + 0 = 0$.
Elegimos la más barata:
$$V(3) = \min\bigl(c_4 + V(4), c_5 + V(5)\bigr) = \min(1, 0) = 0. \quad [\text{acción: saltar 2}]$$
Paso 4 — desde el escalón 2
- Subir 1 (vas a 3): $c_3 + V(3) = 10 + 0 = 10$.
- Saltar 2 (vas a 4): $c_4 + V(4) = 1 + 0 = 1$.
$$V(2) = \min\bigl(c_3 + V(3), c_4 + V(4)\bigr) = \min(10, 1) = 1. \quad [\text{acción: saltar 2}]$$
Paso 5 — desde el escalón 1
- Subir 1 (vas a 2): $c_2 + V(2) = 5 + 1 = 6$.
- Saltar 2 (vas a 3): $c_3 + V(3) = 10 + 0 = 10$.
$$V(1) = \min\bigl(c_2 + V(2), c_3 + V(3)\bigr) = \min(6, 10) = 6. \quad [\text{acción: subir 1}]$$
Una pausa — ¿qué patrón ves?
Para: antes de terminar la tabla, mira lo que llevas escrito. En cada renglón has calculado algo de la forma:
$$V(i) = \min\bigl( c_{i+1} + V(i+1), c_{i+2} + V(i+2)\bigr).$$
O, si quieres pensarlo en términos de “acciones”:
$$V(i) = \min_a \bigl( c(i, a) + V(T(i, a))\bigr)$$
donde $c(i, a)$ es el costo de tomar la acción $a$ desde $i$ (aquí, el costo del escalón al que aterrizas), y $T(i, a)$ es el estado al que llegas. Esto es el principio de optimalidad traducido a matemáticas.
No te preocupes, todavía no le ponemos nombre. Termina la tabla.
Paso 6 — desde el escalón 0
- Subir 1 (vas a 1): $c_1 + V(1) = 2 + 6 = 8$.
- Saltar 2 (vas a 2): $c_2 + V(2) = 5 + 1 = 6$.
$$V(0) = \min\bigl(c_1 + V(1), c_2 + V(2)\bigr) = \min(8, 6) = 6. \quad [\text{acción: saltar 2}]$$
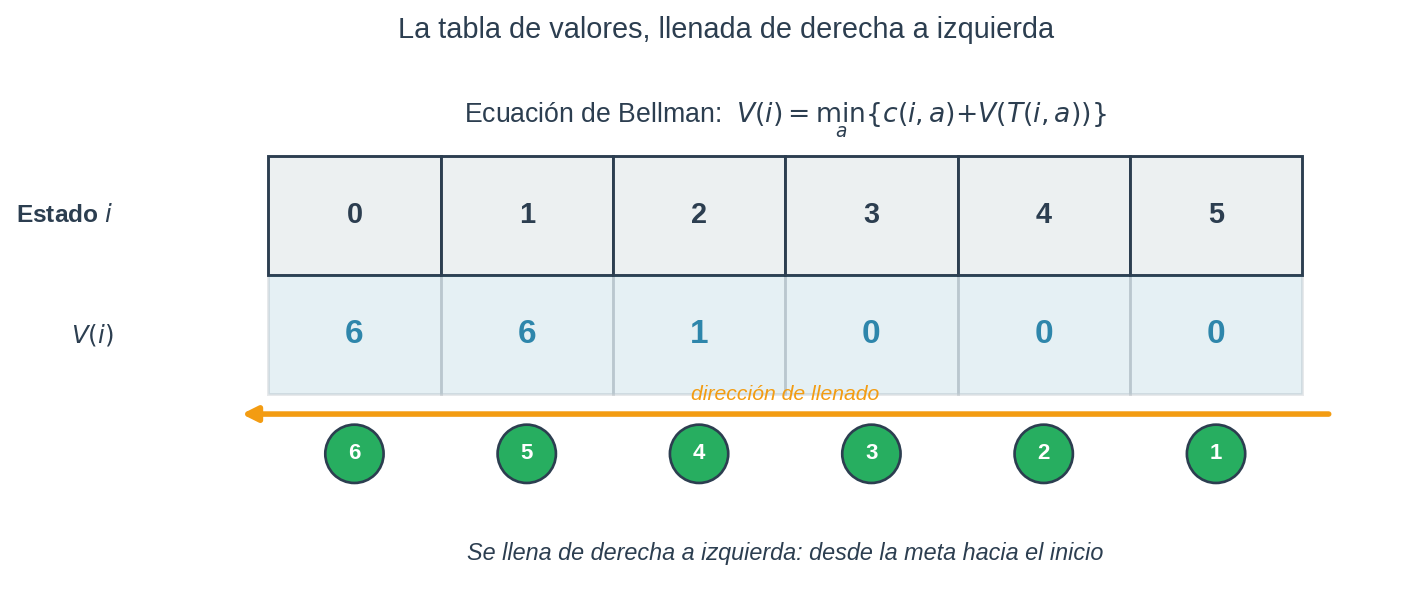
La tabla, llena
| Escalón $i$ | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| Costo $c_i$ | 3 | 2 | 5 | 10 | 1 | 0 |
| Valor $V(i)$ | 6 | 6 | 1 | 0 | 0 | 0 |
| Acción óptima | saltar 2 | subir 1 | saltar 2 | saltar 2 | subir 1 | — |
Política óptima: desde 0 salta 2, desde 2 salta 2, desde 4 sube 1. Trayectoria: $0 \to 2 \to 4 \to 5$. Costo total: los costos de los escalones donde aterrizas son $c_2 + c_4 + c_5 = 5 + 1 + 0 = 6$. Coincide con $V(0) = 6$.
Compara con el codicioso: 0 → 1 → 2 → 4 → 5 pagaba $c_1 + c_2 + c_4 + c_5 = 2 + 5 + 1 + 0 = 8$. La política óptima ahorra exactamente $c_1 = 2$ — el costo del escalón decoy que el codicioso visitó sin necesidad. Lo logró saltando el escalón 1, precisamente porque pensó en la secuencia completa en lugar del siguiente escalón.
Ahora sí, le ponemos nombre
Lo que acabas de escribir cinco veces es la fórmula más importante de la optimización dinámica. Se llama la ecuación de Bellman.
En su forma general, para un problema con acciones $a$, costo inmediato $c(s, a)$ de tomar la acción $a$ en el estado $s$, y función de transición $T(s, a)$ que te dice a qué estado llegas:
$$\boxed{ V(s) = \min_{a} \Bigl\lbrace c(s, a) + V\bigl(T(s, a)\bigr)\Bigr\rbrace }$$
Léela en palabras: “el costo mínimo desde $s$ es el mejor, entre todas las acciones, de ‘lo que pagas ahora por tomar esa acción, más lo que pagarás óptimamente desde donde aterrizas’”.
No es un algoritmo. Es una condición: nos dice qué propiedad satisface una función de valor óptima. El algoritmo que la resuelve (la programación dinámica, bottom-up) lo vamos a ver explícitamente en la sección 21.4 — aunque en realidad, acabas de aplicarlo a mano.
Una vuelta de tuerca: ¿qué pasa si a veces resbalas?
Hasta ahora asumimos que cada acción hace exactamente lo que quieres. La realidad es menos cooperativa. Supón que la escalera está mojada y:
- La acción subir 1 siempre funciona (pasas al escalón siguiente).
- La acción saltar 2 éxito (llegas a $i+2$) con probabilidad $0.8$, pero resbalas (solo avanzas a $i+1$) con probabilidad $0.2$.
Tu trayectoria ya no es determinista. Aún así, el principio de optimalidad se aplica — solo que ahora el costo que esperas pagar depende de dónde esperas aterrizar, no de dónde aterrizas con certeza.
La versión estocástica de la función de valor toma esperanza sobre el siguiente estado:
$$V(s) = \min_{a} \mathbb{E}_{s’ \sim P(\cdot \mid s, a)}\bigl[ c(s, a, s’) + V(s’) \bigr]$$
Para nuestra escalera, el costo de una acción depende solo del escalón donde aterrizas: $c(s, a, s’) = c_{s’}$. Escribiendo la esperanza como suma con probabilidades explícitas:
$$\boxed{ V(s) = \min_{a} \sum_{s’} P(s’ \mid s, a)\bigl[ c_{s’} + V(s’)\bigr]}$$
Esto es la ecuación de Bellman en su forma estocástica. La suma es sobre todos los estados siguientes posibles, ponderada por la probabilidad de aterrizar en cada uno.
Rellenemos la tabla estocástica
Desde el escalón 4 solo hay una acción (subir 1, va a 5 con certeza): $V(4) = c_5 + V(5) = 0 + 0 = 0$.
Desde el escalón 3:
- Acción “subir 1” (determinista, va a 4): $c_4 + V(4) = 1 + 0 = 1$.
- Acción “saltar 2” (va a 5 con prob. 0.8, a 4 con prob. 0.2): $0.8(c_5 + V(5)) + 0.2(c_4 + V(4)) = 0.8 \cdot 0 + 0.2 \cdot 1 = 0.2$.
$$V(3) = \min(1, 0.2) = 0.2. \quad [\text{acción: saltar 2}]$$
Desde el escalón 2:
- “Subir 1” (va a 3): $c_3 + V(3) = 10 + 0.2 = 10.2$.
- “Saltar 2” (va a 4 con prob. 0.8, a 3 con prob. 0.2): $0.8(c_4 + V(4)) + 0.2(c_3 + V(3)) = 0.8 \cdot 1 + 0.2 \cdot 10.2 = 0.8 + 2.04 = 2.84$.
$$V(2) = \min(10.2, 2.84) = 2.84. \quad [\text{acción: saltar 2}]$$
Desde el escalón 1:
- “Subir 1” (va a 2): $c_2 + V(2) = 5 + 2.84 = 7.84$.
- “Saltar 2” (va a 3 con prob. 0.8, a 2 con prob. 0.2): $0.8(c_3 + V(3)) + 0.2(c_2 + V(2)) = 0.8 \cdot 10.2 + 0.2 \cdot 7.84 = 8.16 + 1.568 = 9.728$.
$$V(1) = \min(7.84, 9.728) = 7.84. \quad [\text{acción: subir 1}]$$
Desde el escalón 0:
- “Subir 1” (va a 1): $c_1 + V(1) = 2 + 7.84 = 9.84$.
- “Saltar 2” (va a 2 con prob. 0.8, a 1 con prob. 0.2): $0.8(c_2 + V(2)) + 0.2(c_1 + V(1)) = 0.8 \cdot 7.84 + 0.2 \cdot 9.84 = 6.272 + 1.968 = 8.24$.
$$V(0) = \min(9.84, 8.24) = 8.24. \quad [\text{acción: saltar 2}]$$
Tabla estocástica
| Escalón $i$ | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| $V$ determinista | 6 | 6 | 1 | 0 | 0 | 0 |
| $V$ estocástico | 8.24 | 7.84 | 2.84 | 0.2 | 0 | 0 |
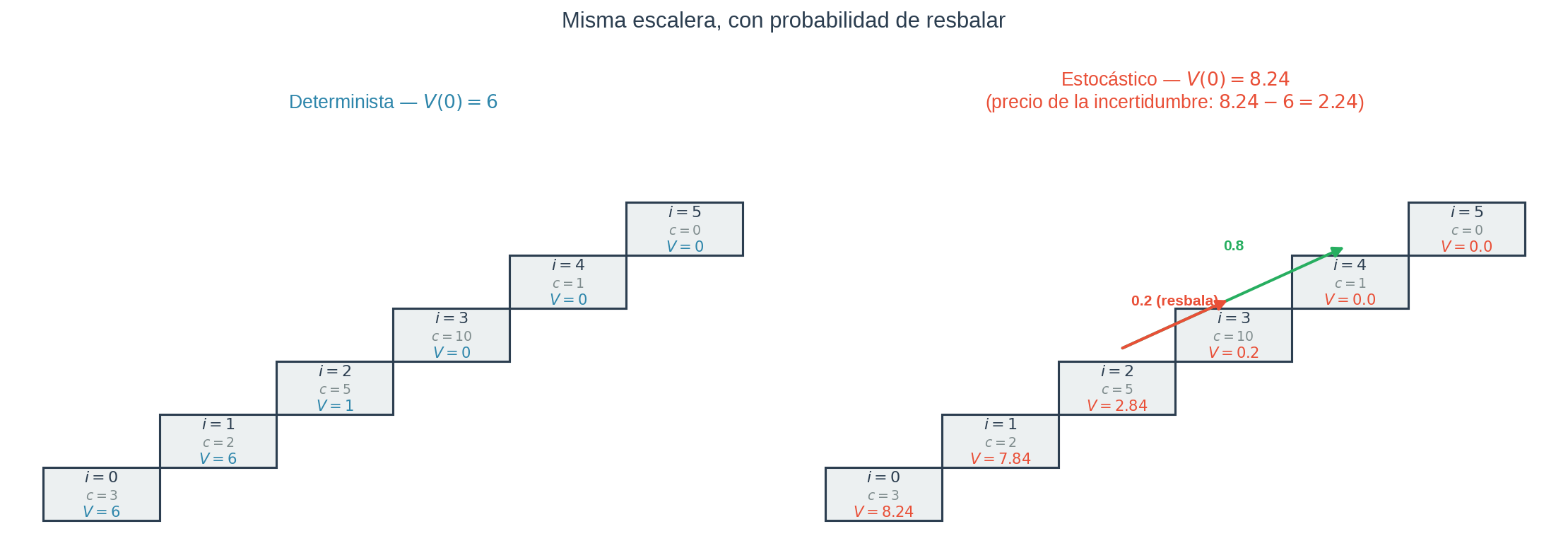
Observación clave. El costo esperado desde el escalón 0 subió de 6 a 8.24. La diferencia, 2.24, es lo que te cuesta la incertidumbre. No estamos haciendo nada peor — estamos tomando las mismas decisiones inteligentes. Simplemente hay caminos donde el mundo no coopera. Ese 2.24 es el precio de la incertidumbre, y es un número que ves, no solo un concepto abstracto.
La política óptima se mantiene en casi todos los escalones — el orden relativo de las acciones sigue siendo el mismo. Lo importante: la misma ecuación, ahora con una esperanza adentro, sigue guiando cada decisión.
Otra vuelta: ¿y si el futuro vale menos que el presente?
Hasta aquí tratamos cada costo como igual de pesado, sin importar cuándo ocurra. Pero los humanos (y los mercados, y los agentes computacionales) rara vez piensan así. Un peso hoy no vale lo mismo que un peso dentro de un año. Un riesgo dentro de 10 turnos pesa menos que un riesgo dentro de 2.
Introducimos un factor de descuento $\gamma \in [0, 1]$ que pondera el futuro. Pero antes de ponerlo en la ecuación, hagámoslo sentir real — $\gamma$ no es un parámetro arbitrario, sale de una historia concreta.
Historia 1 — “la escalera se puede interrumpir”
Supón que, en cada paso, hay una probabilidad $p$ de que algo te obligue a abandonar (se apaga la luz, llegan los exámenes, se acaba el día). Si $p = 0.05$, entonces la probabilidad de que sigas subiendo un paso más después es:
$$\gamma = 1 - p = 0.95.$$
El valor esperado desde un estado ya no es “todo lo que pasa adelante” — es “todo lo que pasa adelante, multiplicado por la probabilidad de que realmente pase”. Y esa probabilidad se acumula: después de $t$ pasos, la probabilidad de seguir activo es $\gamma^t$.
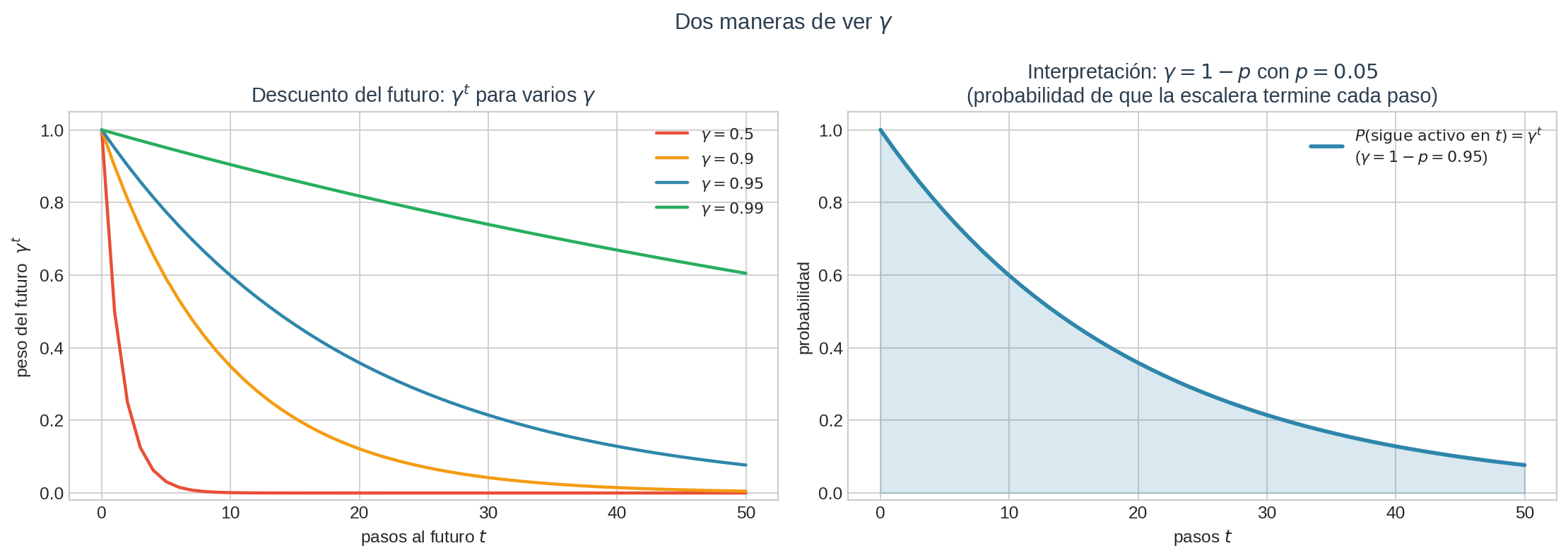
Historia 2 — “un peso hoy vale más que un peso mañana”
Esta la conoces: si te ofrezco 100 pesos hoy o 100 el año entrante, eliges hoy. Porque (a) puedes invertirlo, (b) la inflación lo erosiona, © podrías no estar aquí. Tu cerebro aplica un factor de descuento subjetivo. Si valoras 100 pesos de hoy igual que 105 el año entrante, tu $\gamma$ (anual) es $\approx 0.95$.
Las dos historias llegan al mismo lugar: $\gamma = 0.95$. Es el mismo número, con dos razones posibles para creer en él.
La ecuación de Bellman con descuento
Ahora sí, la ecuación en su forma más general:
$$\boxed{ V(s) = \min_{a} \sum_{s’} P(s’ \mid s, a)\bigl[ c(s, a, s’) + \gamma V(s’)\bigr]}$$
El $\gamma$ multiplica solo al valor futuro $V(s’)$ — el costo inmediato $c(s, a, s’)$ se paga ahora, sin descuento. Así, costos cercanos pesan completo y costos lejanos se van desvaneciendo como $\gamma^t$.
Un paso concreto: $V(1)$ con $\gamma = 0.95$ (determinista)
Desde el escalón 1, con la versión determinista para ver claramente el efecto de $\gamma$:
- Subir 1 (va a 2): $c_2 + \gamma \cdot V(2) = 5 + 0.95 \cdot 1 = 5.95$.
- Saltar 2 (va a 3): $c_3 + \gamma \cdot V(3) = 10 + 0.95 \cdot 0 = 10$.
$$V(1) = \min(5.95, 10) = 5.95. \quad [\text{acción: subir 1}]$$
Sin descuento ($\gamma = 1$) obtenías $V(1) = 6$. Con $\gamma = 0.95$ obtienes $V(1) = 5.95$ — el futuro $V(2) = 1$ se descontó a $0.95$. Si $\gamma$ fuera más chico (digamos $0.5$), tendrías $V(1) = 5 + 0.5 = 5.5$: el presente domina y el futuro se desvanece.
Resumen antes de seguir
Tres formas de la ecuación de Bellman, todas con la misma estructura:
| Caso | Ecuación |
|---|---|
| Determinista | $V(s) = \min_a \lbrace c(s, a) + V(T(s, a)) \rbrace$ |
| Estocástico | $V(s) = \min_a \sum_{s’} P(s’ \mid s, a)[ c(s, a, s’) + V(s’)]$ |
| Estocástico con descuento | $V(s) = \min_a \sum_{s’} P(s’ \mid s, a)[ c(s, a, s’) + \gamma V(s’)]$ |
Cada versión dice lo mismo: el valor futuro desde un estado es el mejor, entre todas las acciones, de ‘(lo que pagas por tomarla) + (lo que pagarás desde donde aterrices)’. Lo único que cambia es qué tan exigentemente modelas la incertidumbre y el futuro.
Maximizar también es posible (para problemas de recompensa en lugar de costo): intercambia $\min$ por $\max$ y llama a $c$ “recompensa $r$”. La estructura es idéntica — de hecho, es la ecuación que verás cuando lleguemos a aprendizaje por refuerzo.
Siguiente: Formular problemas como MDP →