El Problema: Modelos Ocultos de Markov
1. De cadenas de Markov a HMMs
En el módulo 19 estudiamos las cadenas de Markov: en cada paso del tiempo el sistema ocupa un estado, y ese estado es directamente observable. Si el estado es “Soleado” o “Lluvioso”, lo sabemos exactamente.
Pero Lain tiene un problema diferente. Ella no puede ver el cielo desde su habitación. Lo único que puede observar es si la gente en la Red lleva paraguas o no. El clima es real y cambia según reglas de Markov — pero Lain nunca lo ve directamente. Solo ve las consecuencias.
Este es el escenario de un Modelo Oculto de Markov: hay un proceso de Markov corriendo “debajo” (la capa oculta), y en cada paso produce una observación que sí podemos ver (la capa visible).
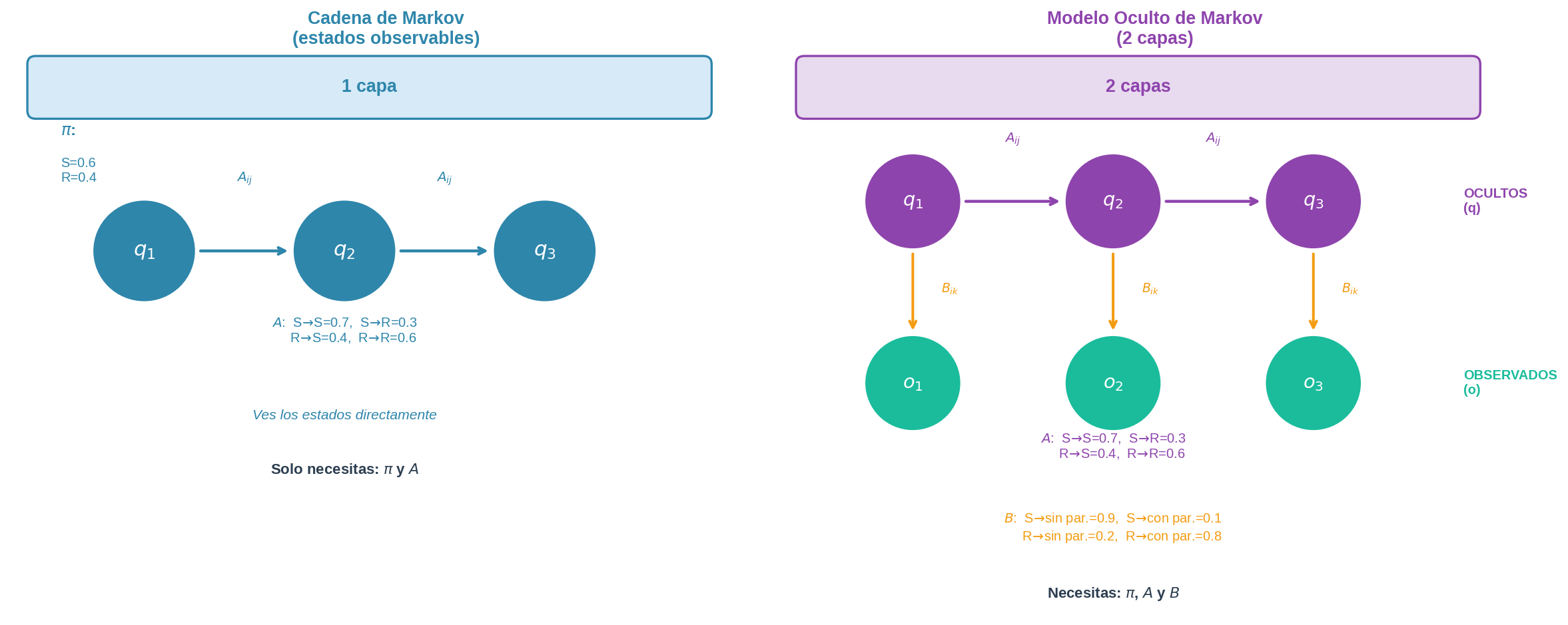
La diferencia central:
| Cadena de Markov | HMM | |
|---|---|---|
| Estados | Observables directamente | Ocultos — no los vemos |
| Lo que vemos | El estado mismo | Una observación generada por el estado |
| Pregunta principal | ¿Cuál es la distribución estacionaria? | ¿Qué podemos inferir sobre los estados ocultos? |
2. Las dos capas del modelo
Un HMM tiene exactamente dos capas:
Capa oculta — la cadena de Markov que no podemos observar:
$$q_1 \to q_2 \to q_3 \to \cdots \to q_T$$
Cada $q_t$ es un estado oculto. Evoluciona según las probabilidades de transición habituales de una cadena de Markov: el siguiente estado depende solo del actual.
Capa visible — las observaciones que sí podemos ver:
$$O_1, \quad O_2, \quad O_3, \quad \ldots, \quad O_T$$
Cada observación $O_t$ es generada independientemente por el estado oculto $q_t$ de ese mismo instante. Dado $q_t$, la observación $O_t$ no depende de nada más — ni del estado anterior ni de las observaciones previas.
El proceso generativo paso a paso
Para fijar la intuición, así es exactamente como un HMM genera una secuencia de longitud $T$:
- Muestrea el estado inicial: $q_1 \sim \pi$ — escoge el primer estado oculto según la distribución inicial.
- Emite la primera observación: $O_1 \sim B_{q_1, \cdot}$ — dado el estado $q_1$, escoge la observación según la fila correspondiente de $B$.
- Transiciona al siguiente estado: $q_2 \sim A_{q_1, \cdot}$ — dado el estado actual $q_1$, escoge el siguiente estado según la fila correspondiente de $A$.
- Emite: $O_2 \sim B_{q_2, \cdot}$
- Repite los pasos 3 y 4 hasta $t = T$.
El resultado es una secuencia de estados ocultos $q_1, q_2, \ldots, q_T$ y una secuencia de observaciones $O_1, O_2, \ldots, O_T$. Nosotros solo vemos la segunda; la primera es lo que queremos inferir.
Notación: $O$, $O_t$ y el índice de emisión. En todo el módulo distinguimos dos objetos:
- $O = (O_1, O_2, \ldots, O_T)$ — la secuencia completa de observaciones (sin subíndice). Es el vector que Lain registra a lo largo de los $T$ días; es la entrada a todos los algoritmos del módulo.
- $O_t$ (con subíndice $t$) — el valor de la observación en el instante $t$: un entero en ${0, 1, \ldots, M-1}$. No es un nombre abstracto sino un número concreto. Por ejemplo, $O_2 = 1$ significa “en el día 2 se observó el símbolo 1 (con paraguas)”.
Este valor $O_t$ actúa como índice de columna en la matriz de emisión $B$. La notación $B_{i,O_t}$ selecciona la entrada de la fila $i$ y la columna $O_t$: si $O_t = 0$, entonces $B_{i,O_t} = B_{i,0}$; si $O_t = 1$, entonces $B_{i,O_t} = B_{i,1}$. En cualquier cálculo concreto, sustituye $O_t$ por el número que corresponde al instante $t$.
Probabilidad conjunta. La probabilidad de una trayectoria específica de estados y observaciones factoriza directamente del proceso generativo:
$$P(O_1, \ldots, O_T, q_1, \ldots, q_T \mid \lambda) = \pi_{q_1} \cdot B_{q_1, O_1} \cdot \prod_{t=2}^{T} A_{q_{t-1}, q_t} \cdot B_{q_t, O_t}$$
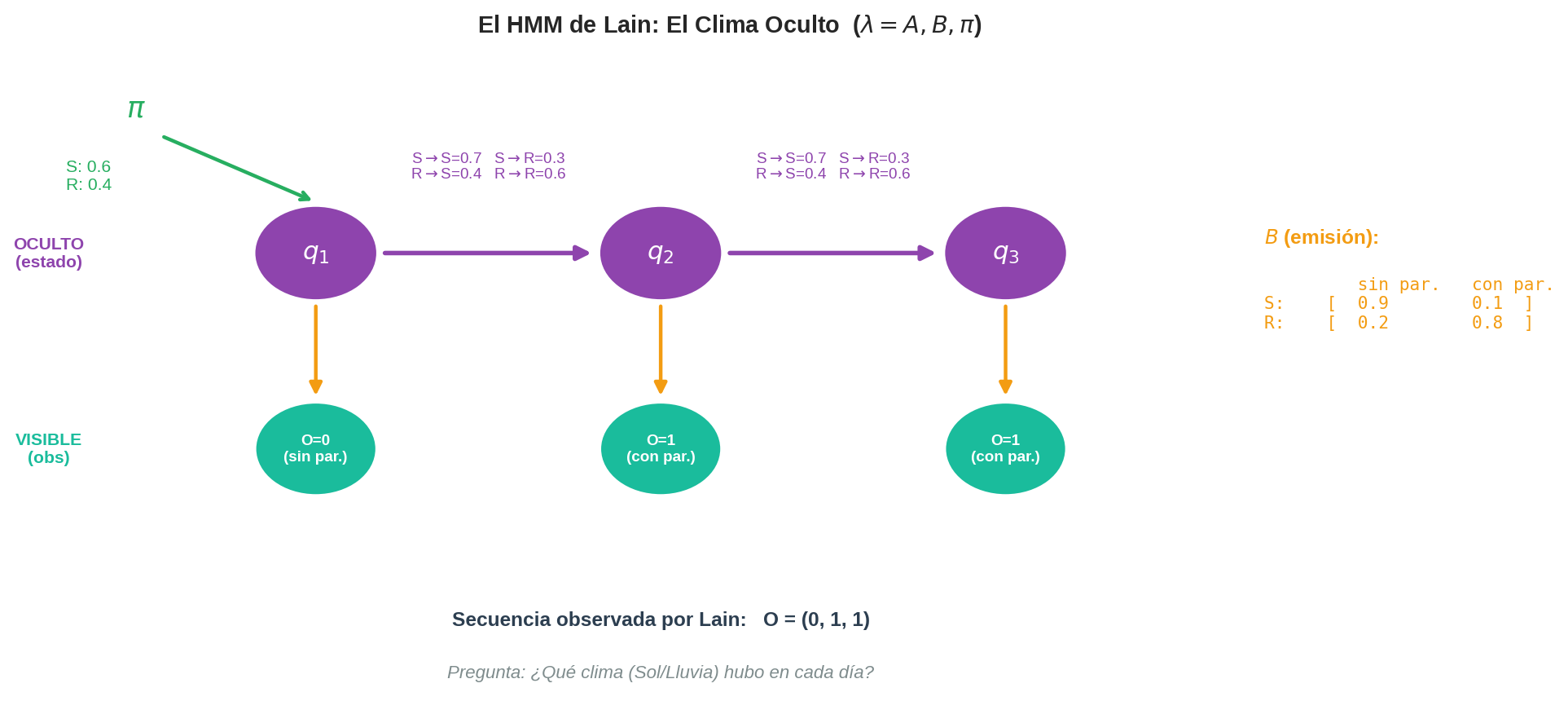
Para el ejemplo de Lain con $T=3$, $q = (S, R, R)$ y $O = (0, 1, 1)$:
$$P(O, q \mid \lambda) = \pi_S \cdot B_{S,0} \cdot A_{SR} \cdot B_{R,1} \cdot A_{RR} \cdot B_{R,1}$$ $$= 0.6 \times 0.9 \times 0.3 \times 0.8 \times 0.6 \times 0.8 = 0.06221$$
Esta es la probabilidad de exactamente esa combinación de estados y observaciones. Para obtener solo $P(O \mid \lambda)$ hay que sumar sobre todas las $N^T$ posibles trayectorias de estados — y eso es justamente el problema que resuelve el algoritmo Forward.
3. Los cinco parámetros del modelo
Un HMM queda completamente especificado por cinco objetos. Al conjunto completo lo llamamos $\lambda = (\pi, A, B)$:
| Símbolo | Nombre | Dimensión | Descripción |
|---|---|---|---|
| $N$ | Número de estados | escalar | Cuántos estados ocultos posibles hay |
| $M$ | Número de observaciones | escalar | Cuántos símbolos de observación posibles hay |
| $\pi_i$ | Distribución inicial | vector $N$ | $P(q_1 = i)$ — probabilidad de comenzar en el estado $i$ |
| $A_{ij}$ | Matriz de transición | $N \times N$ | $P(q_{t+1} = j \mid q_t = i)$ — probabilidad de pasar del estado $i$ al $j$ |
| $B_{ik}$ | Matriz de emisión | $N \times M$ | $P(O_t = k \mid q_t = i)$ — probabilidad de emitir el símbolo $k$ desde el estado $i$; aquí $k \in {0, \ldots, M-1}$ es el valor observado y actúa como índice de columna |
Restricciones (todo debe ser una distribución de probabilidad válida):
$$\sum_{i=1}^N \pi_i = 1, \qquad \sum_{j=1}^N A_{ij} = 1 \text{ para todo } i, \qquad \sum_{k=1}^M B_{ik} = 1 \text{ para todo } i$$
4. El ejemplo de Lain: clima oculto
Usaremos este ejemplo a lo largo de todo el módulo. Es pequeño a propósito — lo suficientemente compacto para seguir cada paso a mano.
Situación: Lain vive encerrada. No puede ver el clima directamente. Cada día observa si las personas en la Red llevan paraguas (observación = 1) o no (observación = 0). El clima cambia día a día siguiendo una cadena de Markov.
Estados ocultos ($N = 2$):
| Estado | Símbolo | Significado |
|---|---|---|
| Soleado | S | El día es soleado |
| Lluvioso | R | El día es lluvioso |
Observaciones ($M = 2$):
| Observación | Símbolo | Significado |
|---|---|---|
| Sin paraguas | 0 | La gente no lleva paraguas |
| Con paraguas | 1 | La gente lleva paraguas |
Distribución inicial $\pi$:
$$\pi_S = 0.6, \qquad \pi_R = 0.4$$
Interpretación: el 60 % de los días Lain asume que comienza soleado.
Matriz de transición $A$:
$$A = \begin{pmatrix} 0.7 & 0.3 \\ 0.4 & 0.6 \end{pmatrix} \qquad \begin{array}{l} \text{fila S: } P(S \to S)=0.7,\quad P(S \to R)=0.3 \\ \text{fila R: } P(R \to S)=0.4,\quad P(R \to R)=0.6 \end{array}$$
Interpretación: si hoy es soleado, mañana hay 70 % de chance de que siga soleado. Si hoy llueve, hay 60 % de chance de que siga lloviendo.
Matriz de emisión $B$:
$$B = \begin{pmatrix} 0.9 & 0.1 \\ 0.2 & 0.8 \end{pmatrix} \qquad \begin{array}{l} \text{fila S: } P(O=0 \mid S)=0.9,\quad P(O=1 \mid S)=0.1 \\ \text{fila R: } P(O=0 \mid R)=0.2,\quad P(O=1 \mid R)=0.8 \end{array}$$
Interpretación: cuando el día es soleado, casi nadie lleva paraguas (90 %). Cuando llueve, la mayoría sí lleva paraguas (80 %).
Secuencia de observaciones de Lain ($T = 3$):
$$O = (O_1, O_2, O_3) = (0, 1, 1)$$
En lenguaje natural: el primer día nadie lleva paraguas; el segundo y tercer día, todos llevan paraguas. Lain quiere saber qué clima corresponde a esta secuencia.
5. Los tres problemas que resolveremos
Con el modelo definido, hay tres preguntas que Lain (o cualquier usuario de HMMs) puede querer responder:
Problema 1 — Evaluación: Dado el modelo $\lambda = (\pi, A, B)$ y la secuencia observada $O = (0, 1, 1)$, ¿cuál es $P(O \mid \lambda)$? Es decir, ¿qué tan bien explica este modelo lo que observó Lain?
→ Algoritmo Forward (o Backward). Sección 20.2 y 20.3.
Problema 2 — Decodificación: Dado el modelo y la secuencia observada, ¿cuál es la secuencia de estados ocultos más probable $q_1^∗, q_2^∗, q_3^∗$?
→ Algoritmo de Viterbi. Sección 20.4.
Problema 3 — Aprendizaje: Dados solo los datos de observaciones (sin saber los estados ocultos), ¿cómo ajustar $\pi$, $A$, $B$ para maximizar $P(O \mid \lambda)$?
→ Algoritmo Baum-Welch. Sección 20.5.