22.1 — El problema de aprendizaje
“Una distribución de probabilidad tiene el monopolio de la verdad. Nosotros solo vemos muestras.”
El problema formal de predicción
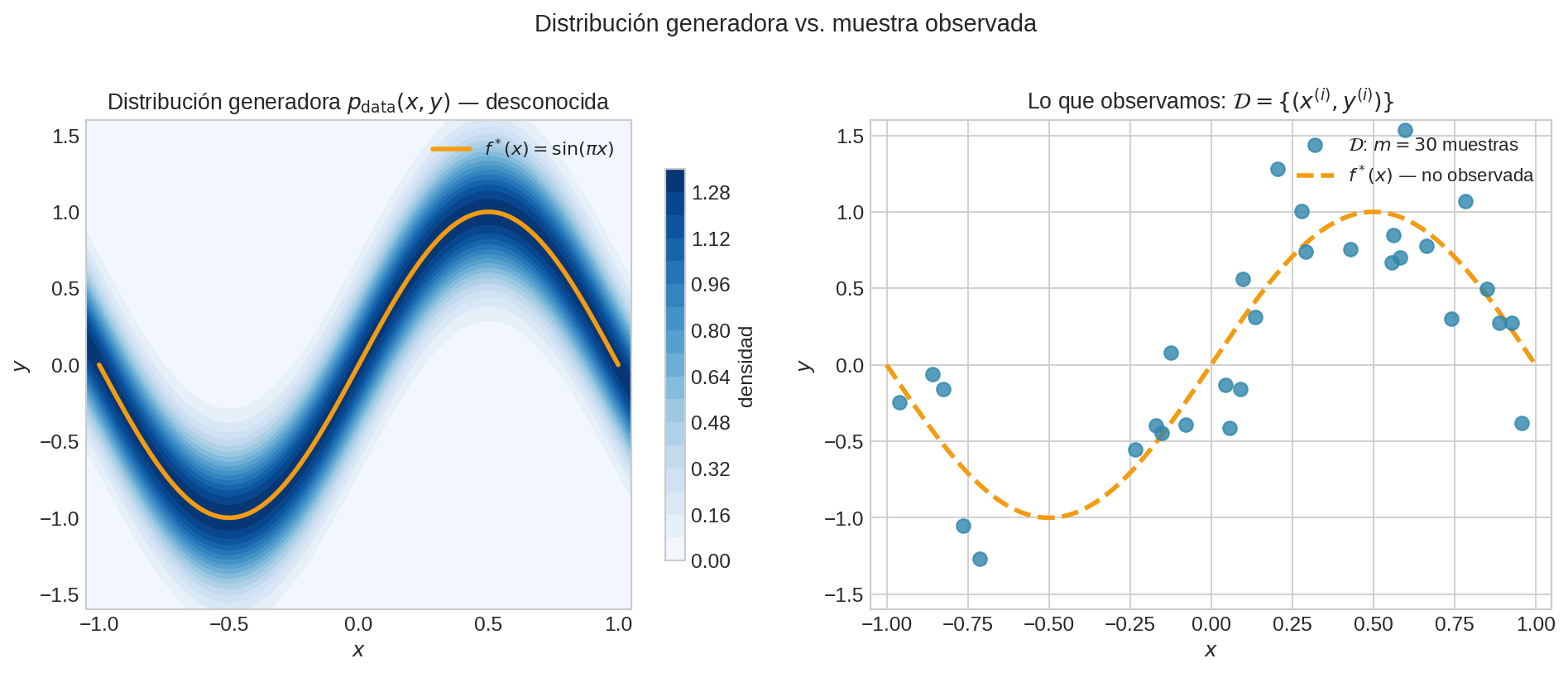
Hay un mundo real del que nunca veremos todo. Solo vemos datos.
Sea $\mathcal{X}$ el espacio de entradas (features) y $\mathcal{Y}$ el espacio de salidas. Asumimos que los pares $(x, y)$ se generan i.i.d. desde una distribución conjunta desconocida:
$$ (x, y) \sim p_{\text{data}}(x, y) $$
El objetivo es aprender una función $f: \mathcal{X} \to \mathcal{Y}$ que prediga bien. “Bien” lo mide una función de pérdida $L: \mathcal{Y} \times \mathcal{Y} \to \mathbb{R}_{\geq 0}$.
El error de generalización
El error de generalización de una función $f$ mide cuánto falla en promedio sobre datos nuevos generados desde $p_{\text{data}}$:
$$ \boxed{R(f) = \mathbb{E}_{(x,y) \sim p_{\text{data}}}[L(f(x), y)]} $$
Este es el objeto que queremos minimizar — no el error sobre los datos de entrenamiento, sino el error esperado sobre datos no vistos. El problema: $p_{\text{data}}$ es desconocida. No podemos computar $R(f)$ directamente.
El predictor de Bayes
El mínimo posible de $R(f)$ sobre todas las funciones medibles define el error de Bayes $R^{∗}$:
$$ R^{∗} = \min_{f} R(f), \qquad f^{∗}(x) = \arg\min_{y’} \mathbb{E}[L(y’, y) \mid x] $$
Para MSE: $f^{∗}(x) = \mathbb{E}[y \mid x]$. Para 0-1 loss: $f^{∗}(x) = \arg\max_c P(y=c \mid x)$. El error de Bayes $R^{∗} > 0$ cuando $y$ tiene ruido irreducible dado $x$ — no hay modelo que lo elimine.
El error empírico
Solo tenemos un conjunto de entrenamiento $\mathcal{D} = {(x^{(i)}, y^{(i)})}_{i=1}^m$, i.i.d. de $p_{\text{data}}$. Definimos el error empírico (o riesgo empírico):
$$ \boxed{\hat{R}(f; \mathcal{D}) = \frac{1}{m} \sum_{i=1}^{m} L(f(x^{(i)}), y^{(i)})} $$
Por la ley de los grandes números, $\hat{R}(f; \mathcal{D}) \xrightarrow{m \to \infty} R(f)$ para $f$ fija. El problema central de ML es que minimizamos $\hat{R}$ pero queremos minimizar $R$.
Parámetros e hiperparámetros
Dado un conjunto de hipótesis $\mathcal{H} = {f_\theta : \theta \in \Theta}$, el aprendizaje es optimización:
$$ \hat{\theta} = \arg\min_{\theta \in \Theta} \hat{R}(f_\theta; \mathcal{D}) $$
Definición. Los parámetros $\theta$ son las variables internas del modelo aprendidas por minimizar $\hat{R}$ sobre los datos de entrenamiento.
$$ \boxed{\theta^{∗} = \arg\min_{\theta} \hat{R}(f_\theta; \mathcal{D}_{\text{train}})} $$
Definición. Los hiperparámetros son cantidades que controlan la capacidad o la regularización del modelo y que no se pueden fijar minimizando $\hat{R}$ — hacerlo introduce sesgo. Deben elegirse con datos separados.
La distinción no es arbitraria: es una consecuencia directa del problema de generalización que veremos en 22.2.
Ejemplos canónicos
Regresión lineal
$\mathcal{X} = \mathbb{R}^d$, $\mathcal{Y} = \mathbb{R}$, $L(y’, y) = (y’ - y)^2$ (MSE).
$$ f_\theta(x) = \theta^\top x + b, \qquad \theta \in \mathbb{R}^d,\ b \in \mathbb{R} $$
Riesgo empírico:
$$ \hat{R}(\theta, b; \mathcal{D}) = \frac{1}{m} \sum_{i=1}^m (x^{(i)\top}\theta + b - y^{(i)})^2 = \frac{1}{m}|\mathbf{X}\theta - \mathbf{y}|^2 $$
El mínimo sin restricciones tiene solución cerrada: $\theta^{∗} = (\mathbf{X}^\top \mathbf{X})^{-1}\mathbf{X}^\top \mathbf{y}$.
Regresión logística (clasificación binaria)
$\mathcal{X} = \mathbb{R}^d$, $\mathcal{Y} = {0, 1}$, pérdida de entropía cruzada.
$$ f_\theta(x) = \sigma(\theta^\top x) = \frac{1}{1 + e^{-\theta^\top x}} $$
$$ \hat{R}(\theta; \mathcal{D}) = -\frac{1}{m}\sum_{i=1}^m \left[ y^{(i)} \log f_\theta(x^{(i)}) + (1 - y^{(i)}) \log(1 - f_\theta(x^{(i)})) \right] $$
Este $\hat{R}$ es convexo en $\theta$ — el mínimo existe y se halla con descenso de gradiente (Módulo 7).
La tripleta T / P / E de Mitchell
Tom Mitchell (1997) definió ML de forma operacional: un programa aprende de la experiencia E respecto a una clase de tareas T medidas por desempeño P, si su desempeño en T mejora con E.
| Componente | Regresión lineal | Clasificación logística |
|---|---|---|
| T (Tarea) | Predecir $y \in \mathbb{R}$ | Predecir clase $y \in {0,1}$ |
| P (Desempeño) | MSE en datos nuevos | Exactitud / log-loss en datos nuevos |
| E (Experiencia) | Pares $(x^{(i)}, y^{(i)})$ i.i.d. | Pares $(x^{(i)}, y^{(i)})$ i.i.d. |
La definición es útil porque P se mide sobre datos no vistos — no sobre $\mathcal{D}_{\text{train}}$. Esto anticipa exactamente el problema de generalización.
El error de generalización como hoja de ruta
Todo el módulo gira en torno a una pregunta: ¿cuánto se aleja el error de generalización de $\hat{f}$ del mínimo posible $R^{∗}$?
Para responderla necesitamos un pivote teórico: el oráculo $f_{\mathcal{H}}^{∗}$, el mejor predictor dentro de $\mathcal{H}$ si tuviéramos acceso a $p_{\text{data}}$:
$$ f_{\mathcal{H}}^{∗} = \arg\min_{f \in \mathcal{H}} R(f) $$
Sumando y restando $R(f_{\mathcal{H}}^{∗})$, el exceso de error de generalización se parte en dos brechas (detalle completo en 22.2):
$$ R(\hat{f}) - R^{∗} = \underbrace{(R(f_{\mathcal{H}}^{∗}) - R^{∗})}_{\varepsilon_{\text{approx}}} + \underbrace{(R(\hat{f}) - R(f_{\mathcal{H}}^{∗}))}_{\varepsilon_{\text{estim}}} $$
- $\varepsilon_{\text{approx}}$ (error de aproximación): brecha entre el predictor de Bayes $f^{∗}$ y el mejor posible dentro de $\mathcal{H}$. Controlado por la capacidad de $\mathcal{H}$.
- $\varepsilon_{\text{estim}}$ (error de estimación): brecha entre el oráculo $f_{\mathcal{H}}^{∗}$ y lo que realmente obtenemos $\hat{f}$ con datos finitos. Controlado por $m$ y la complejidad de $\mathcal{H}$.
Esta tensión — más capacidad reduce $\varepsilon_{\text{approx}}$ pero aumenta $\varepsilon_{\text{estim}}$ — es el dilema fundamental del aprendizaje automático.
Siguiente: Generalización →