| Notebook | Colab |
|---|---|
| Notebook 01 — Cadenas y simulación |
Cadenas de Markov
“The future depends on the past only through the present.”
Este es el corazón formal del módulo. Aquí definimos qué es una cadena de Markov, identificamos sus componentes, y — lo más importante — simulamos trayectorias paso a paso para construir intuición antes de pasar a las propiedades teóricas en la sección 3.
1. Intuición: procesos con amnesia
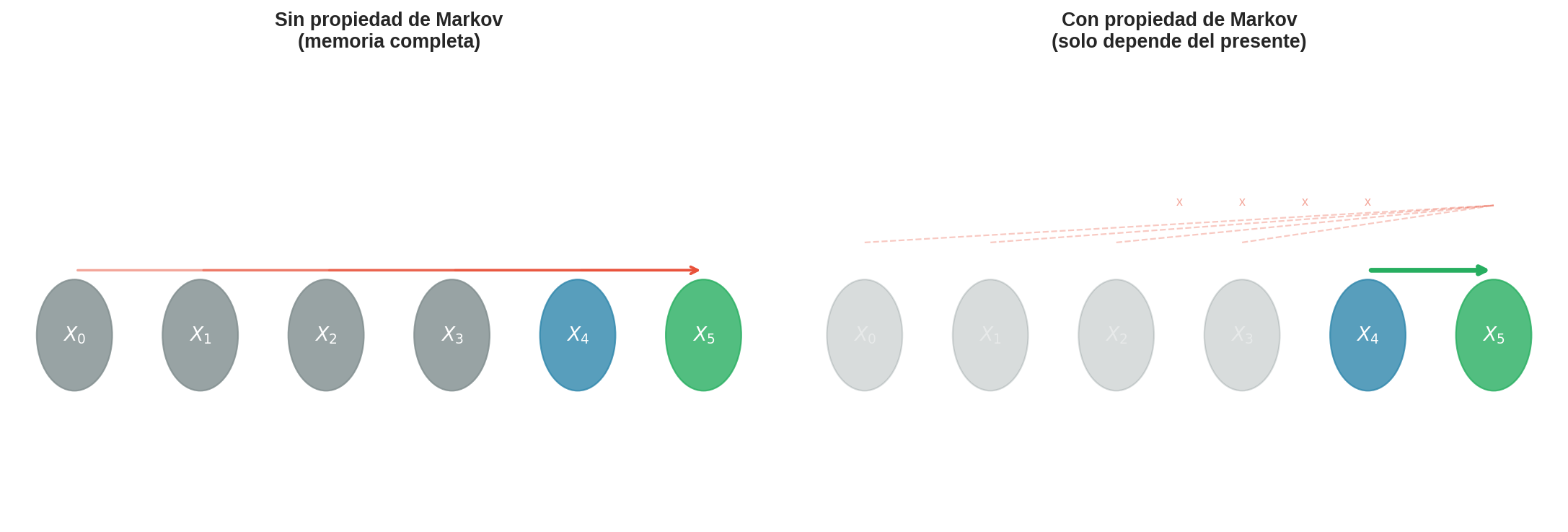
Un proceso de Markov es un sistema que recuerda dónde está pero olvida cómo llegó ahí.
Tres analogías:
- Juego de mesa: tu siguiente movimiento depende de la casilla donde estás, no de las casillas que visitaste antes. No importa si llegaste a la casilla 14 desde la 10 o desde la 20 — las reglas solo miran tu posición actual.
- Clima: la probabilidad de lluvia mañana depende del clima de hoy (soleado, nublado, lluvioso), no del clima de la semana pasada. Hoy contiene toda la información relevante.
- Autocorrector: la sugerencia de la siguiente palabra depende de la última palabra que escribiste, no de todo el párrafo anterior. El modelo mira tu estado actual — la palabra más reciente — y propone la siguiente.
En los tres casos el patrón es el mismo: el futuro depende del presente, no de la historia completa. Formalizamos esta idea a continuación.
2. La propiedad de Markov
Sea ${X_0, X_1, X_2, \ldots}$ una secuencia de variables aleatorias que toman valores en un conjunto finito de estados $S$. La secuencia satisface la propiedad de Markov si para todo $t \geq 0$ y para todos los estados $i, j, i_0, \ldots, i_{t-1} \in S$:
$$P(X_{t+1} = j \mid X_t = i,; X_{t-1} = i_{t-1},; \ldots,; X_0 = i_0) ;=; P(X_{t+1} = j \mid X_t = i)$$
En palabras: la probabilidad de ir al estado $j$ en el siguiente paso depende únicamente del estado actual $i$, no de la secuencia completa de estados anteriores. Toda la historia queda resumida en la posición actual.
Esto no significa que la cadena no tenga estructura temporal — la tiene. Significa que toda la información útil para predecir el futuro ya está contenida en el presente. Condicionar en más historia no aporta nada.
Comparación con secuencias i.i.d.
| Secuencia i.i.d. (Módulos 5/12) | Cadena de Markov (Módulo 19) | |
|---|---|---|
| Cada valor depende de… | Nada (independiente) | Solo el valor anterior |
| Memoria | 0 | 1 |
| ¿Aplica LLN? | Sí (clásica) | Sí (teorema ergódico, sección 04) |
| Ejemplo | Lanzamientos de moneda | Letras en un texto |
En el módulo 5 probamos la Ley de los Grandes Números para secuencias independientes. En el módulo 12 la usamos para justificar Monte Carlo. Aquí veremos que la LLN también aplica a secuencias con dependencia de un paso — pero la demostración requiere maquinaria nueva (sección 04).
3. Componentes de una cadena de Markov
Una cadena de Markov queda completamente especificada por cuatro componentes:
| Componente | Símbolo | Descripción | Ejemplo (V/C) |
|---|---|---|---|
| Estados | $S = {s_1, \ldots, s_k}$ | El conjunto de situaciones posibles | ${V, C}$ |
| Prob. de transición | $p_{ij} = P(X_{t+1} = j \mid X_t = i)$ | Probabilidad de ir del estado $i$ al estado $j$ | $P(C \to V) = 0.52$ |
| Matriz de transición | $\mathbf{P}$ | Matriz $k \times k$ donde la entrada $(i, j)$ es $p_{ij}$ | Matriz $2 \times 2$ |
| Distribución inicial | $\pi_0$ | Distribución sobre estados en $t = 0$: ¿dónde empieza la cadena? | “Empezamos en C” |
Matriz estocástica. La matriz de transición $\mathbf{P}$ tiene una propiedad fundamental: cada fila suma 1. Esto es porque cada fila representa una distribución de probabilidad sobre los posibles estados siguientes. Si estás en el estado $i$, la fila $i$ de $\mathbf{P}$ te dice las probabilidades de cada destino posible:
$$\sum_{j=1}^{k} p_{ij} = 1 \quad \text{para todo } i$$
Cada fila es un vector de probabilidades. Cada columna corresponde a un estado destino. La posición $(i, j)$ responde la pregunta: “si estoy en $i$, ¿con qué probabilidad paso a $j$?”
4. Ejemplo 1: Vocales y Consonantes
Este ejemplo está directamente inspirado en el trabajo original de Markov (1913), quien analizó las alternancias entre vocales y consonantes en Eugenio Oneguin de Pushkin. Aquí hacemos lo análogo con texto en español.
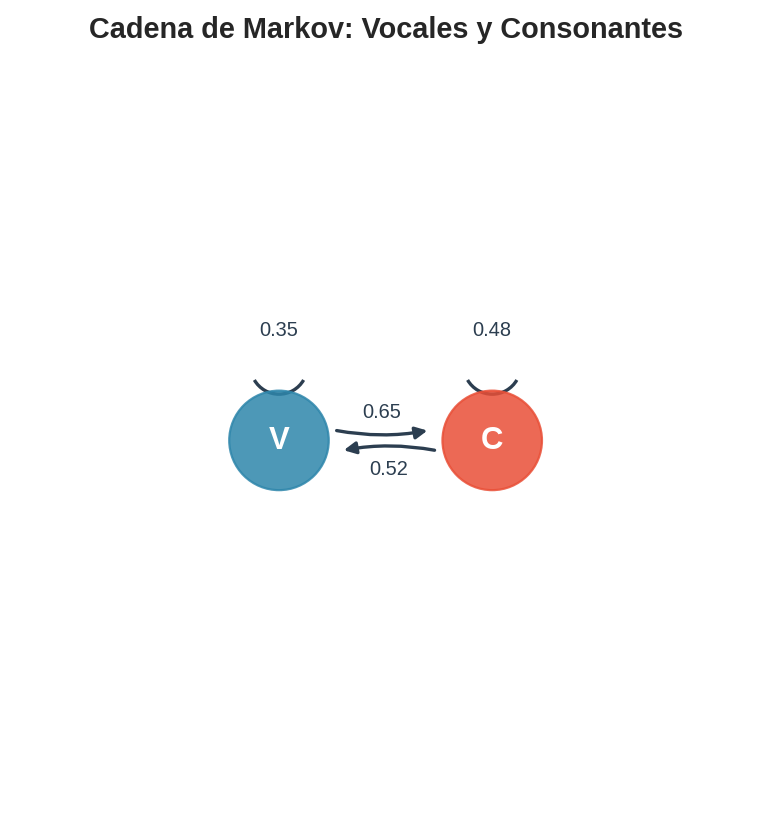
Estados: $S = {V, C}$ — Vocal y Consonante.
Matriz de transición (estimada a partir de texto en español):
| a $V$ | a $C$ | |
|---|---|---|
| desde $V$ | 0.35 | 0.65 |
| desde $C$ | 0.52 | 0.48 |
Cómo leer la matriz: cada fila es el estado actual (de dónde vienes); cada columna es el estado siguiente (a dónde vas). La entrada $P_{ij}$ es la probabilidad de pasar del estado $i$ al estado $j$ en un paso. Es decir:
- $P(V \to V) = 0.35$, $P(V \to C) = 0.65$ — después de una vocal, es más probable que siga una consonante.
- $P(C \to V) = 0.52$, $P(C \to C) = 0.48$ — después de una consonante, vocal y consonante son casi equiprobables, con ligera ventaja para vocal.
Verificación: $0.35 + 0.65 = 1.0$ y $0.52 + 0.48 = 1.0$. Cada fila suma 1 (las probabilidades de salir de un estado deben sumar 1). $\checkmark$
Simulación paso a paso
Simular una cadena de Markov es un proceso de tres pasos que se repite:
- Consultar la fila del estado actual en $\mathbf{P}$
- Generar un número aleatorio $u \sim \text{Uniforme}(0, 1)$
- Usar umbrales acumulados para decidir el siguiente estado
Vamos a recorrer 5 pasos completos, empezando en el estado $C$.
Paso 1: Estado = C
Consultamos la fila $C$ de $\mathbf{P}$:
$$P(V \mid C) = 0.52, \quad P(C \mid C) = 0.48$$
Construimos los intervalos acumulados:
- $[0,; 0.52) \to V$
- $[0.52,; 1) \to C$
Generamos $u = 0.23$. Como $0.23 < 0.52$, caemos en el primer intervalo.
Siguiente estado: V
Paso 2: Estado = V
Consultamos la fila $V$ de $\mathbf{P}$:
$$P(V \mid V) = 0.35, \quad P(C \mid V) = 0.65$$
Intervalos:
- $[0,; 0.35) \to V$
- $[0.35,; 1) \to C$
Generamos $u = 0.71$. Como $0.71 \geq 0.35$, caemos en el segundo intervalo.
Siguiente estado: C
Paso 3: Estado = C
Fila $C$: $P(V \mid C) = 0.52$, $P(C \mid C) = 0.48$.
Generamos $u = 0.44$. Como $0.44 < 0.52 \to V$.
Siguiente estado: V
Paso 4: Estado = V
Fila $V$: $P(V \mid V) = 0.35$, $P(C \mid V) = 0.65$.
Generamos $u = 0.12$. Como $0.12 < 0.35 \to V$.
Siguiente estado: V
Paso 5: Estado = V
Fila $V$: $P(V \mid V) = 0.35$, $P(C \mid V) = 0.65$.
Generamos $u = 0.89$. Como $0.89 \geq 0.35 \to C$.
Siguiente estado: C
Resumen de la trayectoria
| Paso | Estado | $u$ | Fila consultada | Siguiente |
|---|---|---|---|---|
| 0 | C | — | — | — |
| 1 | C | 0.23 | $P(V \mid C)=0.52$, $P(C \mid C)=0.48$ | V |
| 2 | V | 0.71 | $P(V \mid V)=0.35$, $P(C \mid V)=0.65$ | C |
| 3 | C | 0.44 | $P(V \mid C)=0.52$, $P(C \mid C)=0.48$ | V |
| 4 | V | 0.12 | $P(V \mid V)=0.35$, $P(C \mid V)=0.65$ | V |
| 5 | V | 0.89 | $P(V \mid V)=0.35$, $P(C \mid V)=0.65$ | C |
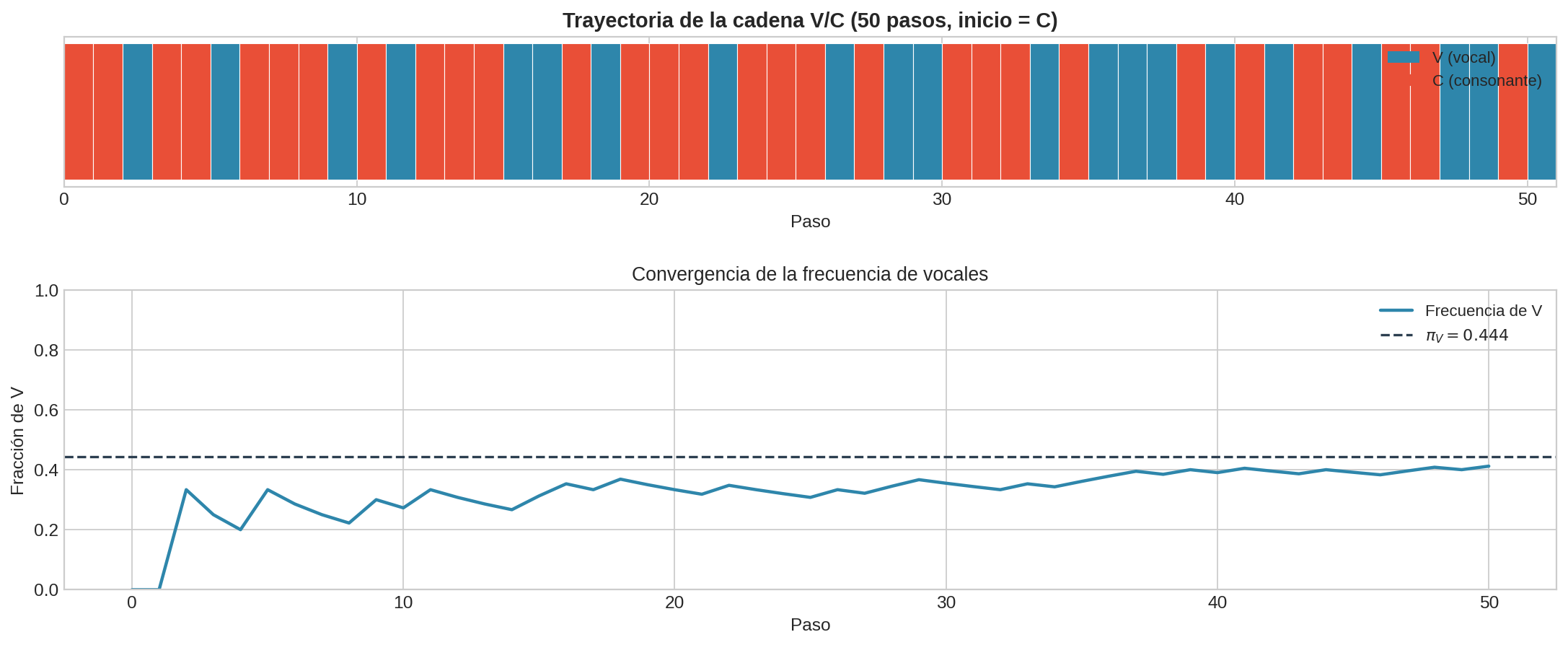
Trayectoria completa: $C \to V \to C \to V \to V \to C$
Después de 5 pasos: $V$ apareció 3 veces, $C$ apareció 2 veces. Frecuencia empírica de $V$: $3/5 = 0.60$.
La proporción estacionaria verdadera es $\pi_V \approx 0.444$ (la calcularemos en la sección 03). Con solo 5 pasos estamos lejos — pero la convergencia llegará. El teorema ergódico (sección 04) garantiza que, conforme $n \to \infty$, la frecuencia empírica converge a $\pi$.
5. Ejemplo 2: Regímenes de mercado
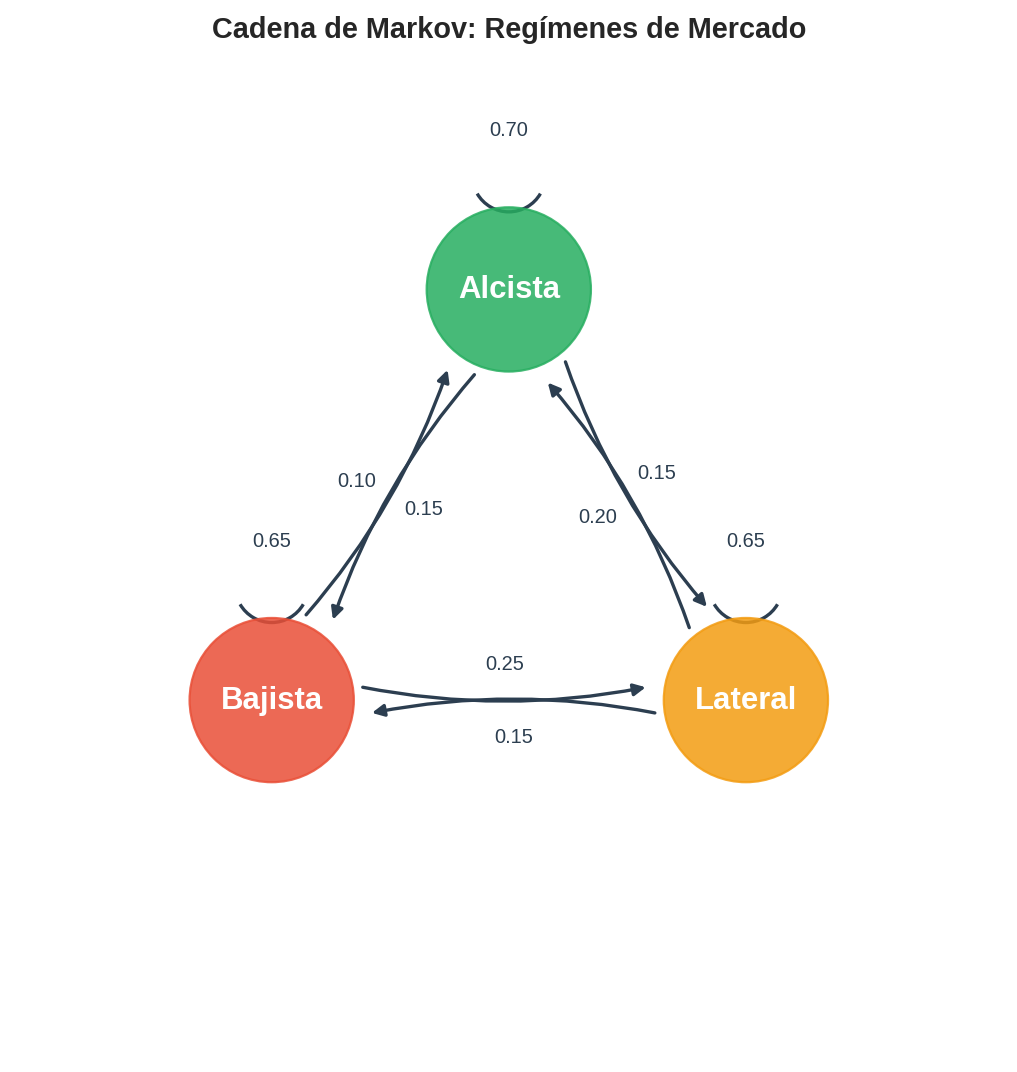
Las cadenas de Markov aparecen naturalmente en finanzas. Un modelo clásico describe el mercado como alternando entre tres regímenes:
Estados: $S = {\text{Alcista (Bull)},; \text{Bajista (Bear)},; \text{Lateral (Flat)}}$
Matriz de transición:
| a Alcista | a Bajista | a Lateral | |
|---|---|---|---|
| desde Alcista | 0.70 | 0.15 | 0.15 |
| desde Bajista | 0.10 | 0.65 | 0.25 |
| desde Lateral | 0.20 | 0.15 | 0.65 |
Cómo leer la matriz: cada fila es el régimen actual; cada columna es el régimen siguiente. La entrada $P_{ij}$ es la probabilidad de pasar del régimen $i$ al régimen $j$ en un período.
Observaciones:
- Los valores diagonales son altos (0.70, 0.65, 0.65) — los regímenes tienden a persistir.
- Un mercado bajista tiene 25% de probabilidad de pasar a lateral, pero solo 10% de pasar directamente a alcista.
- Cada fila suma 1: $0.70 + 0.15 + 0.15 = 1.0$, etc. $\checkmark$
Simulación con 3 estados
Con tres estados, los umbrales acumulados tienen dos puntos de corte en vez de uno. Para el estado Alcista:
$$P(\text{Alcista} \mid \text{Alcista}) = 0.70, \quad P(\text{Bajista} \mid \text{Alcista}) = 0.15, \quad P(\text{Lateral} \mid \text{Alcista}) = 0.15$$
Intervalos acumulados:
- $[0,; 0.70) \to \text{Alcista}$
- $[0.70,; 0.85) \to \text{Bajista}$
- $[0.85,; 1.0) \to \text{Lateral}$
Simulemos 3 pasos empezando en Alcista:
Paso 1: Estado = Alcista. $u = 0.42$. Como $0.42 < 0.70 \to$ Alcista. El mercado se mantiene.
Paso 2: Estado = Alcista. $u = 0.78$. Como $0.70 \leq 0.78 < 0.85 \to$ Bajista. Cambio de régimen.
Paso 3: Estado = Bajista. Intervalos para Bajista: $[0, 0.10) \to$ Alcista, $[0.10, 0.75) \to$ Bajista, $[0.75, 1.0) \to$ Lateral. $u = 0.91$. Como $0.91 \geq 0.75 \to$ Lateral.
Trayectoria: Alcista $\to$ Alcista $\to$ Bajista $\to$ Lateral.
El mecanismo es idéntico al ejemplo anterior — la única diferencia es que con $k = 3$ estados necesitamos $k - 1 = 2$ puntos de corte en los umbrales acumulados. Para $k$ estados arbitrarios, necesitamos $k - 1$ puntos de corte.
6. Predicción a múltiples pasos: potencias de la matriz
Hasta ahora hemos calculado transiciones de un solo paso: dado que estoy en $V$ ahora, ¿cuál es la probabilidad de estar en $C$ en el siguiente paso? Eso es simplemente leer la entrada correspondiente de $\mathbf{P}$.
Pero ¿qué pasa si quiero saber la probabilidad de ir de $V$ a $C$ en 2 pasos? ¿O en 10 pasos?
La idea: sumar sobre todos los caminos intermedios
Para ir de $V$ a $V$ en 2 pasos, debo pasar por algún estado intermedio en el paso 1. Ese estado intermedio puede ser $V$ o $C$ — no hay otra opción. Entonces:
Camino 1: V ──0.35──▶ V ──0.35──▶ V probabilidad = 0.35 × 0.35 = 0.1225
Camino 2: V ──0.65──▶ C ──0.52──▶ V probabilidad = 0.65 × 0.52 = 0.3380
─────────────────────────────────────
Total P²[V,V] = 0.4605
Los dos caminos son mutuamente excluyentes (no puedes estar en $V$ y $C$ al mismo tiempo en el paso 1), así que simplemente sumamos sus probabilidades.
Notación: ¿qué es $P[V, V]$?
$P[V, V]$ es simplemente la entrada de la fila $V$, columna $V$ de la matriz $\mathbf{P}$ — es decir, la probabilidad de pasar de $V$ a $V$ en un solo paso. En general, $P[i, j]$ = probabilidad de ir de estado $i$ a estado $j$ en un paso.
Por qué esto es exactamente multiplicación de matrices
Recordemos cómo se multiplican dos matrices. La entrada $(i,j)$ del producto $\mathbf{A} \cdot \mathbf{B}$ se obtiene tomando el renglón $i$ de $\mathbf{A}$ y la columna $j$ de $\mathbf{B}$, multiplicando término a término y sumando:
$$(\mathbf{A} \cdot \mathbf{B}){ij} = \sum A_{ik} \cdot B_{kj}$$
Apliquemos esto a $\mathbf{P}^2 = \mathbf{P} \cdot \mathbf{P}$ con la cadena V/C. Para calcular la entrada $(V, V)$:
Renglón V de P → [ 0.35 0.65 ] (probabilidades de salir de V en el paso 1)
× ×
Columna V de P → [ 0.35 0.52 ] (probabilidades de llegar a V en el paso 2)
+
= 0.35×0.35 + 0.65×0.52 = 0.4605
¿Por qué el renglón $V$ de $\mathbf{P}$? Ese renglón es la distribución de salida desde $V$: $P[V,V]=0.35$ y $P[V,C]=0.65$. Describe el primer paso.
¿Por qué la columna $V$ de $\mathbf{P}$? Esa columna contiene las probabilidades de llegar a $V$ desde cualquier estado: $P[V,V]=0.35$ y $P[C,V]=0.52$. Describe el segundo paso.
Al multiplicar término a término y sumar, cada producto $P[V,k] \cdot P[k,V]$ es la probabilidad de usar el estado intermedio $k$:
- $k = V$: probabilidad del camino $V \to V \to V$ es $P[V,V] \cdot P[V,V] = 0.35 \times 0.35$
- $k = C$: probabilidad del camino $V \to C \to V$ es $P[V,C] \cdot P[C,V] = 0.65 \times 0.52$
Sumar sobre todos los $k$ posibles da la probabilidad total de llegar a $V$ en 2 pasos desde $V$. Esto es exactamente la multiplicación renglón-por-columna:
$$\mathbf{P}^2[i,, j] = \sum_{k \in S} P[i, k] \cdot P[k, j]$$
La multiplicación matricial suma automáticamente sobre todos los intermedios. No es una coincidencia — es exactamente la misma operación. Por eso $\mathbf{P}^2 = \mathbf{P} \cdot \mathbf{P}$ da las probabilidades de transición en 2 pasos, y en general:
$$P(X_{t+n} = j \mid X_t = i) = (\mathbf{P}^n)_{ij}$$
Cálculo completo de $\mathbf{P}^2$ para V/C
Aplicando la fórmula a las 4 entradas (la cadena V/C tiene 2 estados, así que $\mathbf{P}^2$ es una matriz $2 \times 2$):
$\mathbf{P}^2[V, V]$ — probabilidad de $V \to \text{(algo)} \to V$:
$$\mathbf{P}^2[V, V] = P[V,V] \cdot P[V,V] + P[V,C] \cdot P[C,V]$$
$$= 0.35 \times 0.35 + 0.65 \times 0.52 = 0.1225 + 0.338 = 0.4605$$
El primer término es el camino $V \to V \to V$; el segundo es $V \to C \to V$. Se suman porque son caminos mutuamente excluyentes.
$\mathbf{P}^2[V, C]$ — probabilidad de $V \to \text{(algo)} \to C$:
$$\mathbf{P}^2[V, C] = P[V,V] \cdot P[V,C] + P[V,C] \cdot P[C,C]$$
$$= 0.35 \times 0.65 + 0.65 \times 0.48 = 0.2275 + 0.312 = 0.5395$$
Verificación: $0.4605 + 0.5395 = 1.0$ $\checkmark$ — la fila de $\mathbf{P}^2$ también debe sumar 1.
$\mathbf{P}^2[C, V]$ — probabilidad de $C \to \text{(algo)} \to V$:
$$\mathbf{P}^2[C, V] = P[C,V] \cdot P[V,V] + P[C,C] \cdot P[C,V]$$
$$= 0.52 \times 0.35 + 0.48 \times 0.52 = 0.182 + 0.2496 = 0.4316$$
$\mathbf{P}^2[C, C]$ — probabilidad de $C \to \text{(algo)} \to C$:
$$\mathbf{P}^2[C, C] = P[C,V] \cdot P[V,C] + P[C,C] \cdot P[C,C]$$
$$= 0.52 \times 0.65 + 0.48 \times 0.48 = 0.338 + 0.2304 = 0.5684$$
Verificación: $0.4316 + 0.5684 = 1.0$ $\checkmark$
La matriz resultado es:
| a $V$ | a $C$ | |
|---|---|---|
| desde $V$ | 0.4605 | 0.5395 |
| desde $C$ | 0.4316 | 0.5684 |
Nota que las filas de $\mathbf{P}^2$ son más parecidas entre sí que las de $\mathbf{P}$ original — la influencia del estado inicial ya se está diluyendo.
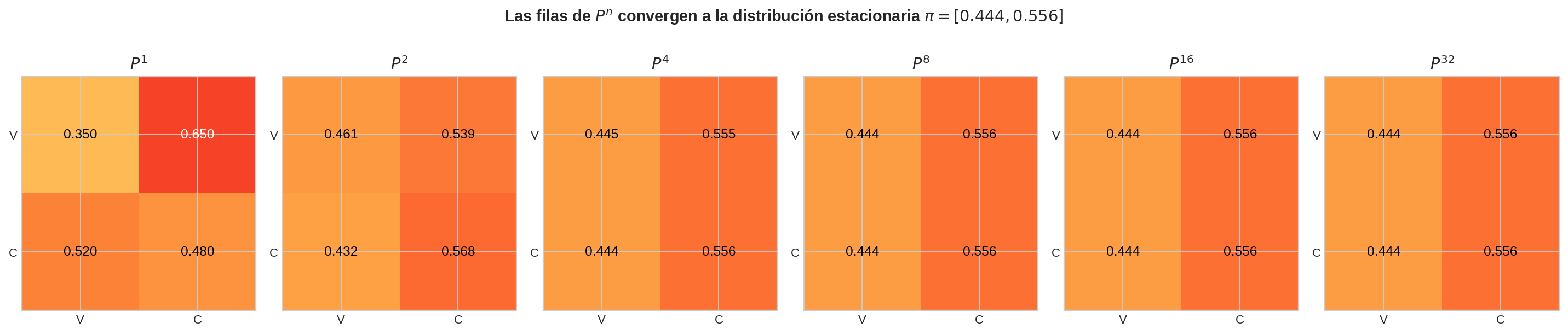
Convergencia de $\mathbf{P}^n$
Algo notable ocurre si calculamos potencias cada vez más altas:
| Potencia | $\mathbf{P}^n[V,V]$ | $\mathbf{P}^n[V,C]$ | $\mathbf{P}^n[C,V]$ | $\mathbf{P}^n[C,C]$ |
|---|---|---|---|---|
| 1 | 0.350 | 0.650 | 0.520 | 0.480 |
| 2 | 0.461 | 0.539 | 0.432 | 0.568 |
| 4 | 0.446 | 0.554 | 0.443 | 0.557 |
| 8 | 0.444 | 0.556 | 0.444 | 0.556 |
| 16 | 0.444 | 0.556 | 0.444 | 0.556 |
Las filas se vuelven idénticas. Independientemente de si empezamos en $V$ o en $C$, después de suficientes pasos las probabilidades de estar en cada estado convergen al mismo vector:
$$\pi \approx (0.444,; 0.556)$$
La cadena olvida su estado inicial. Los valores convergidos $[\pi_V, \pi_C] = [0.444, 0.556]$ forman la distribución estacionaria $\pi$ — la definiremos formalmente en la sección 03 y demostraremos que la convergencia siempre ocurre (bajo ciertas condiciones) en la sección 04.
7. Implementación en Python
La simulación que hicimos a mano se traduce directamente a código:
import numpy as np
def simular_cadena(P, estado_inicial, n_pasos):
"""
Simula una cadena de Markov.
Args:
P : matriz de transición (numpy array k×k)
estado_inicial: índice del estado inicial (0, 1, ..., k-1)
n_pasos : número de pasos a simular
Returns:
lista de estados visitados (longitud n_pasos + 1)
"""
estados = [estado_inicial]
for _ in range(n_pasos):
actual = estados[-1]
siguiente = np.random.choice(len(P), p=P[actual])
estados.append(siguiente)
return estados
La línea clave es np.random.choice(len(P), p=P[actual]) — hace exactamente lo que hicimos a mano: consulta la fila del estado actual y genera el siguiente estado según esas probabilidades.
Ejemplo de uso
# Cadena Vocales/Consonantes
P_vc = np.array([
[0.35, 0.65], # Fila V
[0.52, 0.48], # Fila C
])
nombres = ['V', 'C']
# Simular 20 pasos empezando en C (índice 1)
trayectoria = simular_cadena(P_vc, estado_inicial=1, n_pasos=20)
print("Trayectoria:", [nombres[s] for s in trayectoria])
# Ejemplo de salida: ['C', 'V', 'C', 'V', 'V', 'C', 'C', 'V', 'C', 'V', ...]
# Frecuencia empírica de V
freq_V = sum(1 for s in trayectoria if s == 0) / len(trayectoria)
print(f"Frecuencia empírica de V: {freq_V:.3f}")
print(f"Valor teórico (π_V): 0.444")
Con 20 pasos la frecuencia empírica ya estará más cerca de 0.444 que nuestro intento de 5 pasos. Con 10,000 pasos será prácticamente indistinguible — eso es el teorema ergódico en acción.
← Historia · Siguiente: Propiedades →