21.4 — Programación dinámica en detalle
“La ecuación te dice qué buscar. El algoritmo te dice cómo encontrarlo.”
Lo que ya hiciste tiene nombre
Toma un segundo para apreciar algo: cuando llenaste la tabla de $V$ a mano en la sección 21.2, llenaste de derecha a izquierda — desde la meta hacia atrás. Para $V(3)$ necesitabas $V(4)$ y $V(5)$; así que los calculaste primero. Para $V(0)$ necesitabas $V(1)$ y $V(2)$; ya los tenías, así que lo hiciste al final.
Ese proceso tiene un nombre. Se llama programación dinámica tabulada (o bottom-up DP). Lo estuviste haciendo sin darte cuenta. Esta sección es, en gran parte, re-leer lo que ya hiciste con vocabulario técnico — y compararlo contra la alternativa ingenua, para que veas por qué DP no es solo más rápida sino categóricamente distinta de la versión directa.
La versión ingenua — y por qué explota
Supón que, en lugar de llenar la tabla, alguien te pide calcular $V(0)$ directamente usando la ecuación recursiva. Escribes un programa ingenuo:
función OPTIMAL(i):
si i == N: # estado meta, no falta pagar nada
return 0
opciones = [c[i+1] + OPTIMAL(i+1)] # acción "subir 1"
si i+2 ≤ N:
opciones.append(c[i+2] + OPTIMAL(i+2)) # acción "saltar 2"
return min(opciones)
Corre OPTIMAL(0) y te regresa 6. Correcto. ¿Cuál es el problema?
El problema es cuántas veces OPTIMAL se llama a sí misma. Para calcular OPTIMAL(0) necesita OPTIMAL(1) y OPTIMAL(2). Para calcular OPTIMAL(1) necesita OPTIMAL(2) y OPTIMAL(3). Fíjate: OPTIMAL(2) se va a calcular dos veces — una vez para OPTIMAL(0), otra para OPTIMAL(1). Y cada una de esas llamadas no sabe nada de la otra, así que recalcula todo desde cero.
El árbol de llamadas se ve así (truncado a profundidad 4 para que quepa en la página):
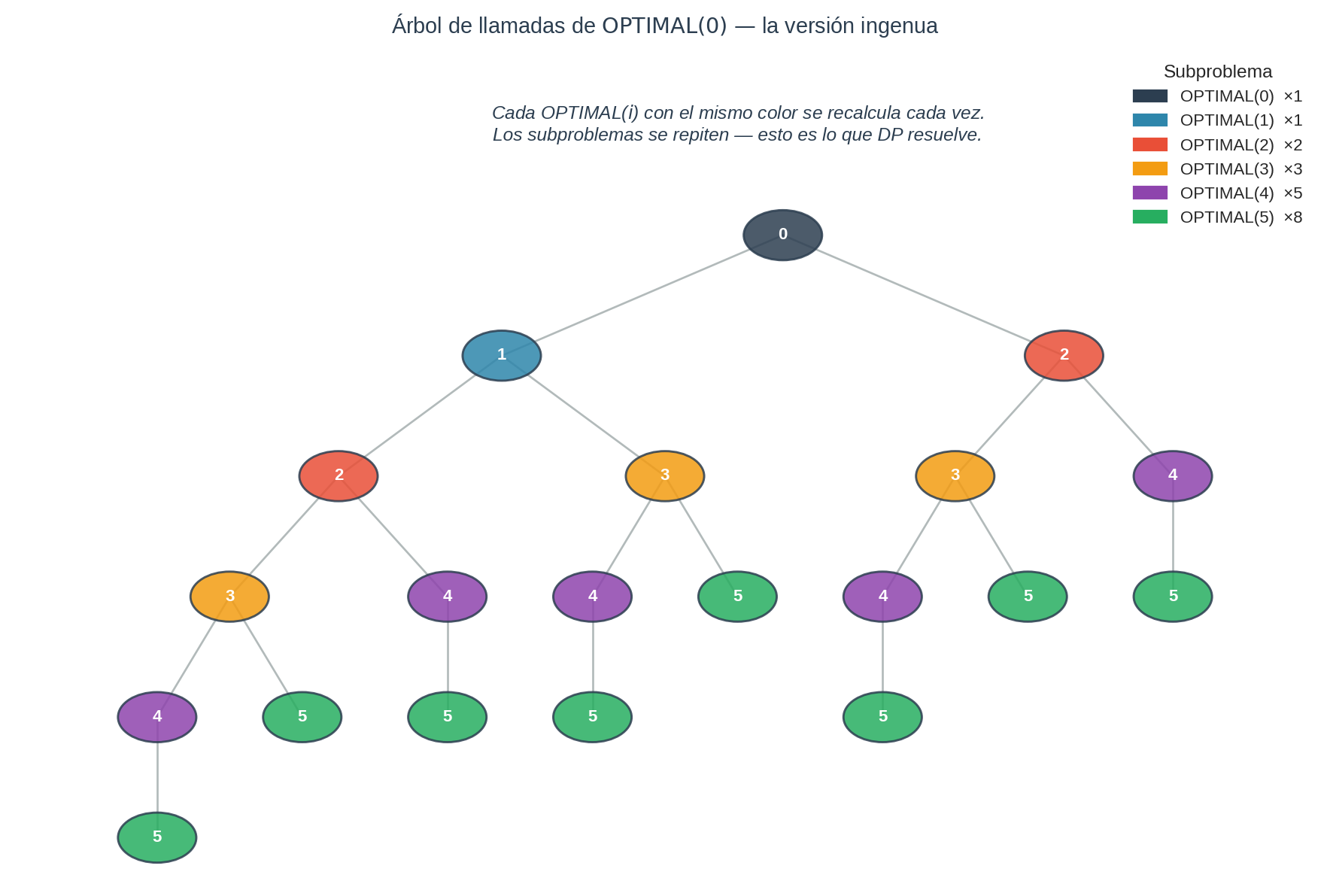
Los nodos del mismo color son el mismo subproblema. Cuéntalos. OPTIMAL(3) aparece varias veces. OPTIMAL(4) aparece aún más. Estamos pagando por calcular lo mismo una y otra vez.
¿Cuánto cuesta? Para esta escalera (acciones 1 o 2 pasos) el número de llamadas sigue una recurrencia tipo Fibonacci:
$$C(N) = 1 + C(N-1) + C(N-2), \qquad C(0) = 1.$$
Crece exponencialmente. Para $N = 30$, son del orden de tres millones y medio de llamadas — para un problema que tiene solo 30 estados. Es ridículo.
La observación que salva el día
El problema no es la ecuación de Bellman. La ecuación está bien — es correcta, es precisa, dice exactamente lo que queremos. El problema es que la versión ingenua recalcula lo que ya sabe.
Solución: calcula cada subproblema una sola vez, guarda el resultado, y reúsalo.
Eso es, literalmente, todo lo que hace la programación dinámica. No es una técnica mística. Es reconocer que los subproblemas se repiten y evitar recalcularlos.
Las dos propiedades que hacen posible DP
Para que este truco funcione, el problema necesita dos propiedades. Si alguna falta, DP no aplica.
Propiedad 1 — Substructure óptima
La solución óptima de un problema se puede construir a partir de las soluciones óptimas de sus subproblemas.
Eso es, literalmente, el principio de optimalidad que vimos en la sección 21.1. Para la escalera: conocer los mejores costos desde los escalones posteriores es suficiente para construir el mejor costo desde el actual.
¿Qué pasa si no se cumple? Imagina un problema donde la “mejor” solución a un subproblema no te sirve para construir la solución global. Entonces no tienes ninguna ecuación recursiva que puedas aprovechar. DP no aplica. Vas a tener que enumerar (o aproximar).
Propiedad 2 — Subproblemas superpuestos
Los mismos subproblemas aparecen repetidamente en la recursión.
Eso es lo que acabamos de ver en el árbol de llamadas: OPTIMAL(2) no es único — se llama desde varios caminos.
¿Qué pasa si no se cumple? Si cada subproblema aparece una sola vez, memoizar no te compra nada. Eso se llama divide y vencerás, no DP. Ordenamiento por mezcla (merge sort), por ejemplo, tiene substructure óptima pero no subproblemas superpuestos — por eso es $O(n \log n)$ y no se beneficia de caché.
DP = substructure óptima + subproblemas superpuestos. Sin las dos, no es DP.
Dos implementaciones de la misma ecuación
Una vez que decides usar DP, tienes dos formas de escribir el algoritmo. Son la misma ecuación; solo cambia el orden en que la recorres.
Memoización (top-down)
Arrancas con la función recursiva ingenua, pero agregas un caché: antes de calcular, pregunta si ya lo tienes.
cache = {}
función OPTIMAL(i):
si i == N: return 0
si i en cache: return cache[i] # ← la línea que cambia todo
opciones = [c[i+1] + OPTIMAL(i+1)]
si i+2 ≤ N:
opciones.append(c[i+2] + OPTIMAL(i+2))
mejor = min(opciones)
cache[i] = mejor
return mejor
OPTIMAL(0)
La llamas una sola vez con OPTIMAL(0). Baja recursivamente, calcula cada subproblema la primera vez, lo guarda, y en cualquier reencuentro lo toma del caché. Cada subproblema se evalúa exactamente una vez. El árbol ingenuo se derrumba a una sola rama del DAG de subproblemas.
Tabulación (bottom-up)
En lugar de recursión, un loop: empiezas donde ya tienes la respuesta (la meta) y avanzas llenando la tabla.
V = arreglo de tamaño N+1
V[N] = 0
para i desde N-1 hasta 0:
opciones = [c[i+1] + V[i+1]] # acción "subir 1"
si i+2 ≤ N:
opciones.append(c[i+2] + V[i+2]) # acción "saltar 2"
V[i] = min(opciones)
return V[0]
No hay recursión, no hay caché explícito — el arreglo V es el caché. Esto es literalmente lo que hiciste con lápiz y papel en la sección 21.2.
Las dos, lado a lado
MEMOIZACIÓN (top-down) │ TABULACIÓN (bottom-up)
─────────────────────────────────────── │ ───────────────────────────────────────
cache = {} │ V = arreglo[N+1]
│ V[N] = 0
función OPTIMAL(i): │
si i == N: return 0 │ para i desde N-1 hasta 0:
si i en cache: return cache[i] │ opts = [c[i+1] + V[i+1]]
opts = [c[i+1] + OPTIMAL(i+1)] │ si i+2 ≤ N:
si i+2 ≤ N: │ opts.append(c[i+2] + V[i+2])
opts.append(c[i+2] + OPTIMAL(i+2)) │ V[i] = min(opts)
cache[i] = min(opts) │
return cache[i] │ return V[0]
│
return OPTIMAL(0) │
Mira lo que hacen ambas: calculan el mismo $V(i) = \min_a \lbrace c(i, a) + V(T(i, a)) \rbrace$ exactamente una vez por cada $i$. La única diferencia es el orden en que lo hacen:
- Memoización: orden guiado por la recursión — DFS desde $V(0)$ hasta las hojas, cachea al regresar.
- Tabulación: orden fijado por el loop — desde $V(N)$ hasta $V(0)$, sin recursión.

Las dos son DP. Las dos tienen la misma complejidad. Cuál elegir depende del contexto: la memoización es natural si ya tienes la versión recursiva escrita; la tabulación es más eficiente en memoria y evita profundidad de pila.
La estructura subyacente: el DAG de subproblemas
¿Por qué esto funciona en general? Porque los subproblemas forman un grafo acíclico dirigido (DAG): cada $V(i)$ depende de $V(i+1)$ y $V(i+2)$, pero nunca depende de sí mismo ni de algo que lo necesite.
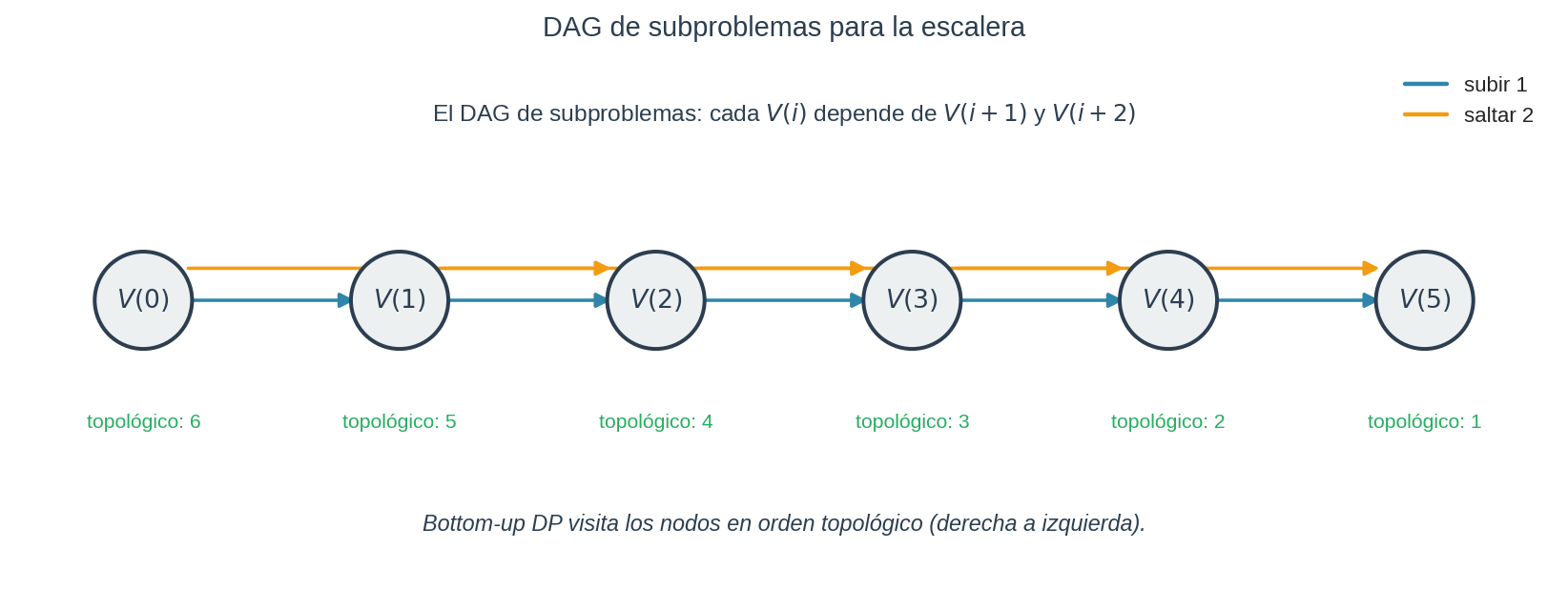
Los nodos del DAG son los subproblemas. Las aristas son las dependencias. Porque es acíclico:
- Existe un orden topológico — un orden lineal donde cada nodo aparece después de todos los que depende.
- Bottom-up DP recorre el DAG en orden topológico (desde los nodos sin dependencias hacia los que dependen de todo).
- Top-down DP (memoizada) recorre el DAG en DFS, y el caché evita visitar el mismo nodo dos veces.
Esta perspectiva es útil porque aplica a cualquier problema de DP, no solo a la escalera. Si puedes dibujar el DAG de subproblemas y no tiene ciclos, DP va a funcionar. Si tiene ciclos, no es un problema de DP estándar (podría ser iteración de valor sobre un MDP con ciclos, pero ese es otro asunto que verás en RL).
La complejidad, sentida
¿Cuánto ganamos con DP sobre la versión ingenua? Mucho. Pero no vale decir “exponencial a lineal” en abstracto; hay que sentirlo.
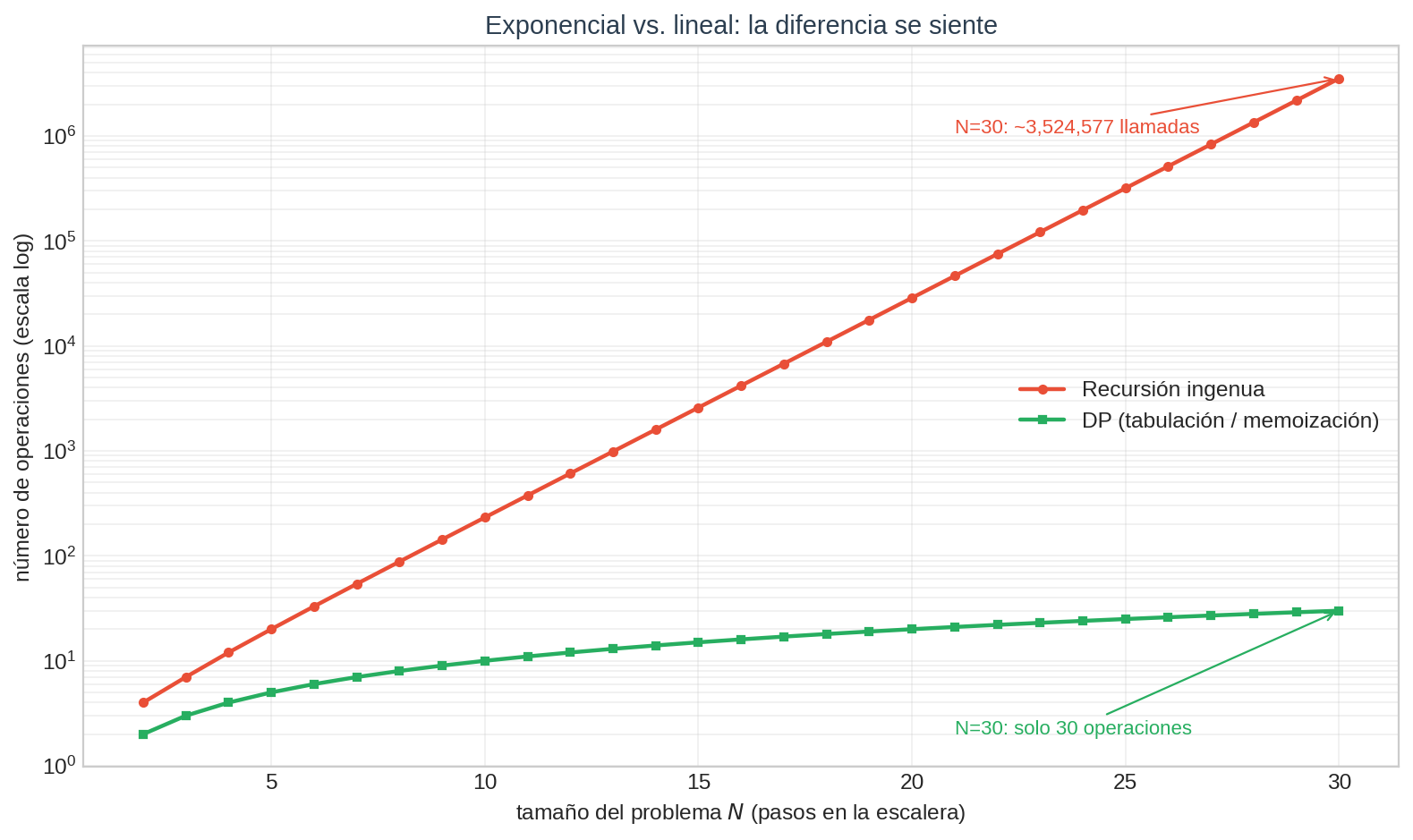
La gráfica está en escala logarítmica. La curva ingenua es una recta subiendo — eso es el comportamiento exponencial. La curva DP es casi plana (es lineal — parece plana porque está comprimida por el log).
Números concretos para $N = 30$:
| Método | Llamadas / operaciones |
|---|---|
| Recursión ingenua | ~3,500,000 |
| DP (memoizada o tabulada) | 30 |
Para $N = 100$, la diferencia se vuelve astronómica: unos $10^{20}$ vs. $100$. La versión ingenua tardaría más que la edad del universo para terminar. La versión DP termina antes de que termines de leer este renglón.
En general para un MDP con DP: complejidad $O(|S| \cdot |A|)$ — el producto del número de estados por el número de acciones. Esa es la brecha: polinomial en el tamaño del problema, no exponencial.
Extraer la política óptima — no basta con $V$
Hay una trampa. La función de valor $V(s)$ te dice qué tan bueno es estar en cada estado. Pero no te dice qué hacer. Para actuar, necesitas la política $\pi(s)$ — una función que, dado un estado, te diga cuál acción tomar.
¿Cómo sale $\pi$ de $V$? Cuando calculaste $V(s) = \min_a \lbrace\ldots\rbrace$, hubo una acción que alcanzó ese mínimo. Esa acción es $\pi^*(s)$ — la decisión óptima en $s$. Para guardarla, simplemente guarda el $\arg\min$ junto con el $\min$:
V = arreglo[N+1]
pi = arreglo[N+1] # ← nuevo: política óptima
V[N] = 0
para i desde N-1 hasta 0:
opciones = [("subir 1", c[i+1] + V[i+1])]
si i+2 ≤ N:
opciones.append(("saltar 2", c[i+2] + V[i+2]))
acción_mejor, valor_mejor = min(opciones por segundo elemento)
V[i] = valor_mejor
pi[i] = acción_mejor
Después, para construir la trayectoria óptima desde el inicio:
estado = 0
trayectoria = [0]
mientras estado < N:
estado = siguiente(estado, pi[estado]) # aplica la acción
trayectoria.append(estado)
En nuestra escalera:
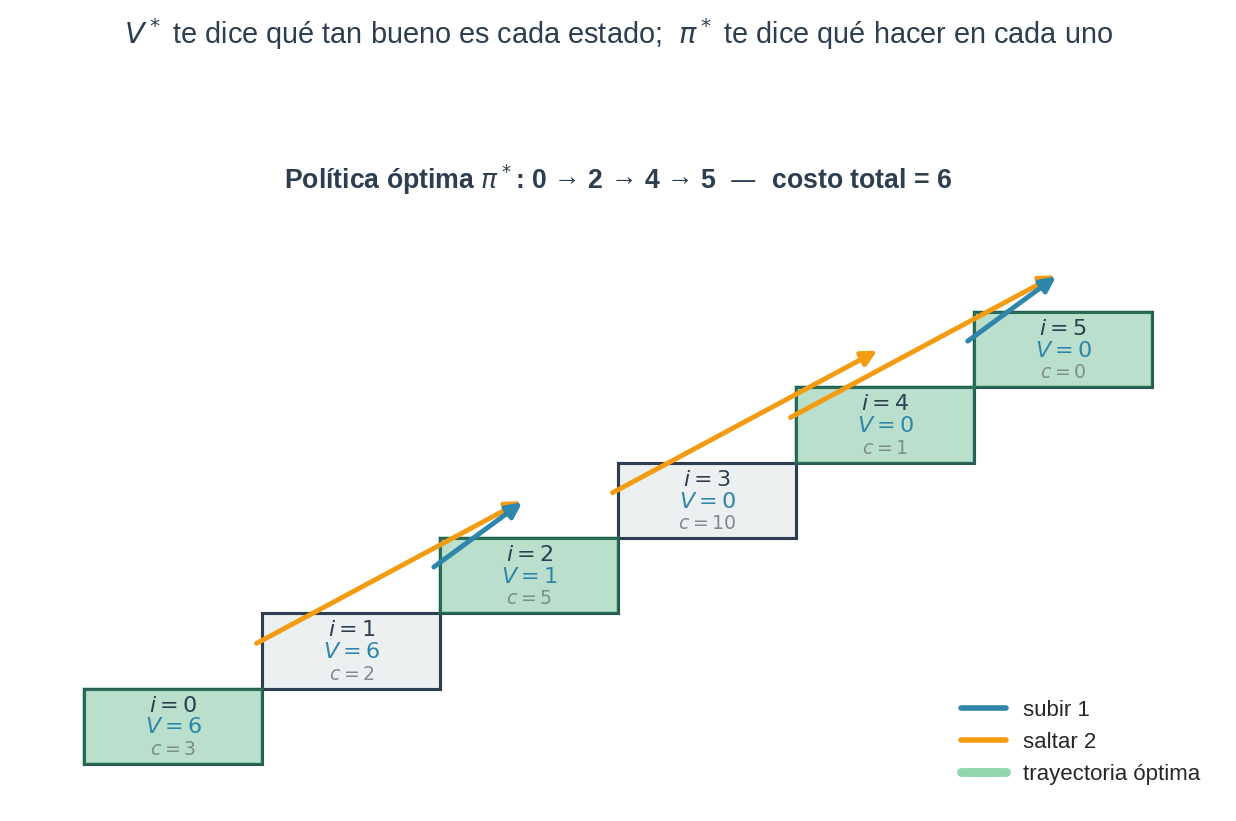
| $i$ | $V(i)$ | $\pi^*(i)$ |
|---|---|---|
| 0 | 6 | saltar 2 |
| 1 | 6 | subir 1 |
| 2 | 1 | saltar 2 |
| 3 | 0 | saltar 2 |
| 4 | 0 | subir 1 |
| 5 | 0 | — (meta) |
Siguiendo la política desde el estado 0: 0 → 2 → 4 → 5, pagando $c_2 + c_4 + c_5 = 6$ en total. Coincide con $V(0) = 6$. La política te da el plan concreto; la función de valor te dice cuánto te va a costar ejecutarlo.
Resumen — dos ideas, separadas
Esta sección cierra la Parte II del módulo. Los conceptos se pueden sintetizar en dos cajas que conviene mantener distintas:
┌─────────────────────────────────────┐ ┌────────────────────────────────────┐
│ ECUACIÓN DE BELLMAN │ │ PROGRAMACIÓN DINÁMICA │
│ (sección 21.2) │ │ (esta sección) │
│ │ │ │
│ Es una CONDICIÓN ESTRUCTURAL: │ ───▶ │ Es un MÉTODO COMPUTACIONAL: │
│ V*(s) = min_a {R + γE[V*(s')]} │ │ • memoización (top-down) │
│ │ │ • tabulación (bottom-up) │
│ No dice cómo encontrar V*, │ │ │
│ solo cómo reconocerla. │ │ Aprovecha la estructura de la │
│ │ │ ecuación para evitar recalcular │
│ │ │ subproblemas. │
└─────────────────────────────────────┘ └────────────────────────────────────┘
El principio. La técnica.
Ambas son aportaciones de Richard Bellman, de hecho — el principio en 1953, la programación dinámica en 1957. Pero son ideas distintas. En cursos tradicionales de algoritmos, DP se enseña sin siquiera mencionar la ecuación de Bellman. En cursos tradicionales de decisión, la ecuación se enseña sin hablar de la estructura del DAG. Aquí las tenemos las dos, y en orden: la ecuación primero (porque es lo que queremos resolver), el algoritmo después (porque es cómo la resolvemos).
Esta distinción va a ser crítica en unas semanas, cuando lleguemos a aprendizaje por refuerzo. Spoiler: RL usa la misma ecuación de Bellman. Lo que cambia es el método para resolverla — ya no es programación dinámica, porque no se cumplen ciertas condiciones. Cuál condición es la que falla, lo vas a descubrir en la siguiente página.
Siguiente: Cierre y consolidación →