| Notebook | Colab |
|---|---|
| Notebook 02 — Ergodicidad |
MCMC: invertir la pregunta
“If you can’t sample from the distribution you want, build a Markov chain that converges to it.”
En las secciones anteriores recorrimos un camino: dada una matriz de transición $\mathbf{P}$, encontramos su distribución estacionaria $\pi$ y probamos que la cadena converge a ella (teorema ergódico). Ahora invertimos la pregunta:
Pregunta inversa: Dada una distribución objetivo $\pi$, ¿podemos CONSTRUIR una cadena de Markov cuya distribución estacionaria sea exactamente $\pi$?
Si la respuesta es sí, entonces simplemente corremos la cadena y recolectamos muestras — el teorema ergódico garantiza que los promedios temporales convergen a las esperanzas bajo $\pi$. Esta inversión es la idea central de MCMC: Markov Chain Monte Carlo.
1. El problema: muestrear de distribuciones complejas
En muchos problemas reales conocemos $\pi(x)$ salvo una constante de normalización:
$$\pi(x) = \frac{\tilde{\pi}(x)}{Z}, \qquad Z = \sum_{x} \tilde{\pi}(x)$$
Conocemos $\tilde{\pi}(x)$ — podemos evaluarlo para cualquier $x$ — pero calcular $Z$ es intractable (puede requerir sumar sobre un número exponencial de estados).
Ejemplo concreto: en inferencia bayesiana, la distribución posterior es
$$P(\theta \mid \text{datos}) = \frac{P(\text{datos} \mid \theta) \cdot P(\theta)}{P(\text{datos})}$$
El numerador (likelihood $\times$ prior) es fácil de evaluar. El denominador $P(\text{datos}) = \int P(\text{datos} \mid \theta) P(\theta), d\theta$ es una integral de alta dimensión — exactamente el tipo de problema que Monte Carlo (Módulo 12) sabe resolver. Pero para usar Monte Carlo necesitamos muestras de la posterior. Y no podemos muestrear directamente de ella porque no conocemos $Z$.
Necesitamos una forma de generar muestras de $\pi$ usando solo evaluaciones de $\tilde{\pi}$.
2. La inversión: dado $\pi$, construir $\mathbf{P}$
La idea es sorprendentemente simple:
- Diseñamos una matriz de transición $\mathbf{P}$ tal que su distribución estacionaria sea $\pi$
- Corremos la cadena durante $T$ pasos
- Recolectamos las muestras $X_0, X_1, \ldots, X_T$
- El teorema ergódico (sección 04) garantiza: $\frac{1}{T}\sum f(X_t) \to \mathbb{E}_\pi[f]$
El paso crucial es el 1: ¿cómo construimos $\mathbf{P}$? Necesitamos una condición que garantice $\pi \mathbf{P} = \pi$.
3. Balance detallado: la condición suficiente
La condición formal
Una cadena satisface balance detallado con respecto a $\pi$ si:
$$\pi(x) \cdot P(x \to y) = \pi(y) \cdot P(y \to x) \qquad \text{para todo } x, y$$
Intuición: flujos en equilibrio
Imagina que $\pi$ describe una población de partículas distribuidas entre los estados. En cada paso, algunas partículas se mueven de un estado a otro.
El flujo de partículas de $x$ a $y$ es:
$$\text{flujo}(x \to y) = \underbrace{\pi(x)}{\text{partículas en } x} \cdot \underbrace{P(x \to y)}{\text{tasa de salto } x \to y}$$
Balance detallado dice: el flujo de $x$ a $y$ es igual al flujo de $y$ a $x$. No hay flujo neto en ninguna dirección.
Es como un sistema de piscinas conectadas por tuberías: si el agua que fluye de la piscina A a la B es igual a la que fluye de B a A, los niveles no cambian. Eso es equilibrio. Y si los niveles no cambian, la distribución es estacionaria.
¿Por qué implica estacionariedad?
Si balance detallado se cumple para todo par $(x, y)$, entonces para cualquier estado $y$:
$$\sum_{x} \pi(x) \cdot P(x \to y) = \sum_{x} \pi(y) \cdot P(y \to x) = \pi(y) \sum_{x} P(y \to x) = \pi(y) \cdot 1 = \pi(y)$$
La primera igualdad usa balance detallado; la última usa que las filas de $\mathbf{P}$ suman 1. Esto dice exactamente que $\pi \mathbf{P} = \pi$ — la distribución es estacionaria.
4. Metropolis-Hastings: el algoritmo
El algoritmo de Metropolis-Hastings construye una cadena que satisface balance detallado con respecto a la distribución objetivo $\pi$.
En lenguaje natural
El algoritmo en cuatro pasos:
- Estás en el estado $x$.
- Propón un movimiento: genera un candidato $y$ desde una distribución de propuesta $q(y \mid x)$. La propuesta más simple: $y = x + \text{ruido}$ (propuesta simétrica).
- Calcula la probabilidad de aceptación:
$$\alpha(x \to y) = \min!\left(1,; \frac{\pi(y)}{\pi(x)}\right)$$
(para propuestas simétricas donde $q(y \mid x) = q(x \mid y)$).
- Decide:
- Con probabilidad $\alpha$: acepta — muévete a $y$
- Con probabilidad $1 - \alpha$: rechaza — quédate en $x$
Repite $T$ veces. Las muestras $X_0, X_1, \ldots, X_T$ convergen a $\pi$.
Pseudocódigo
# ── METROPOLIS-HASTINGS ────────────────────────────────────────────
# Genera T muestras de la distribución objetivo π(x)
# usando solo evaluaciones de π (no necesita la constante Z).
# π puede ser no normalizada (π̃): solo usamos el ratio π(y)/π(x),
# donde la constante Z se cancela.
function METROPOLIS_HASTINGS(π, x_0, T, σ):
# σ = desviación estándar de la propuesta Normal(0, σ)
muestras ← [x_0] # empezamos en x_0
for t = 1, 2, ..., T:
x ← muestras[t-1] # estado actual
y ← x + Normal(0, σ) # [P1] propuesta simétrica
α ← min(1, π(y) / π(x)) # [P2] ratio de aceptación
u ← Uniforme(0, 1) # número aleatorio
if u < α: # [P3] ¿aceptamos?
muestras.append(y) # sí → nos movemos a y
else:
muestras.append(x) # no → nos quedamos en x
return muestras
Los tres pasos clave:
| Paso | Qué hace | Por qué |
|---|---|---|
[P1] Propuesta |
Genera candidato $y$ cerca de $x$ | Explora el espacio de estados |
[P2] Ratio $\alpha$ |
Compara $\pi(y)$ con $\pi(x)$ | Estados más probables se aceptan siempre; menos probables, proporcionalmente |
[P3] Aceptar/rechazar |
Decide si moverse | Garantiza balance detallado |
La regla de aceptación en palabras
- Si $\pi(y) \geq \pi(x)$: el candidato es más probable que el actual → $\alpha = 1$ → aceptar siempre
- Si $\pi(y) < \pi(x)$: el candidato es menos probable → $\alpha = \pi(y)/\pi(x) < 1$ → aceptar con probabilidad proporcional al cociente
La cadena se mueve “cuesta arriba” en $\pi$ siempre, y “cuesta abajo” con probabilidad proporcional a cuánto baja. Esto hace que la cadena pase más tiempo en las regiones de alta probabilidad, que es exactamente lo que queremos.
5. Verificación: ¿por qué satisface balance detallado?
Verifiquemos que el ratio de aceptación de Metropolis-Hastings satisface la condición de balance detallado. Consideremos propuesta simétrica ($q(y \mid x) = q(x \mid y)$).
Caso: $\pi(y) \geq \pi(x)$
El algoritmo acepta $x \to y$ con probabilidad $\alpha(x \to y) = 1$ y acepta $y \to x$ con probabilidad $\alpha(y \to x) = \pi(x)/\pi(y)$.
$$\pi(x) \cdot P(x \to y) = \pi(x) \cdot q(y \mid x) \cdot 1 = \pi(x) \cdot q$$
$$\pi(y) \cdot P(y \to x) = \pi(y) \cdot q(x \mid y) \cdot \frac{\pi(x)}{\pi(y)} = \pi(x) \cdot q$$
Iguales. Balance detallado se cumple. $\checkmark$
El caso $\pi(y) < \pi(x)$ es simétrico — solo se intercambian los roles.
El ratio de aceptación no es arbitrario — está diseñado exactamente para que los flujos se cancelen. Aceptamos siempre hacia estados más probables, y hacia estados menos probables con probabilidad igual al cociente de probabilidades.
6. ¿Por qué converge? — Aplicando las secciones 02–04
Ya tenemos todas las piezas. No necesitamos teoría nueva:
-
Es una cadena de Markov (sección 02): cada paso depende solo del estado actual $x$. El siguiente estado se determina por la propuesta y el ratio de aceptación, ambos funciones de $x$ solamente.
-
Balance detallado → $\pi$ es estacionaria (sección 03): acabamos de verificar que el ratio de Metropolis-Hastings satisface balance detallado con respecto a $\pi$. Por lo tanto, $\pi$ es la distribución estacionaria de la cadena.
-
Bajo condiciones suaves, la cadena es ergódica (sección 03): si la propuesta puede alcanzar cualquier estado (la distribución $q$ tiene soporte en todo el espacio), la cadena es irreducible. El componente de rechazo (quedarse en $x$) funciona como un self-loop, garantizando aperiodicidad.
-
El teorema ergódico aplica (sección 04):
$$\frac{1}{T} \sum_{t=1}^{T} f(X_t) \xrightarrow{T \to \infty} \mathbb{E}_\pi[f]$$
Esto NO es teoría nueva. Es el mismo teorema que demostró Markov para las vocales y consonantes de Pushkin — solo que ahora $\pi$ no es la distribución de letras en un poema, sino una posterior bayesiana o cualquier distribución que queramos muestrear.
7. Burn-in: ¿por qué descartamos las primeras muestras?
El teorema ergódico dice que la cadena converge a $\pi$ — pero no dice que empieza en $\pi$. Si inicializamos en un estado arbitrario $x_0$, las primeras muestras están contaminadas por esa elección.
Recordemos el argumento de acoplamiento de la sección 04: dos cadenas que empiezan en estados distintos eventualmente se encuentran y, desde ese momento, son idénticas. El tiempo que tardan en encontrarse es el tiempo de mezcla (mixing time).
Las muestras anteriores al acoplamiento “recuerdan” dónde empezó la cadena. Las muestras posteriores ya no — son representativas de $\pi$.
En la práctica:
- Corremos la cadena $T$ pasos
- Descartamos las primeras $B$ muestras (burn-in)
- Usamos las $T - B$ restantes como muestras de $\pi$
X_0, X_1, ..., X_B, X_{B+1}, ..., X_T
├── descartadas ──┤├── muestras útiles ──┤
(burn-in) (≈ distribuidas según π)
¿Cómo elegir $B$? No hay respuesta universal. En la práctica: graficar la traza de la cadena ($X_t$ vs $t$) y buscar el punto donde la cadena “se estabiliza” — deja de derivar sistemáticamente y empieza a fluctuar alrededor de una región estable. Descartar todo antes de ese punto.
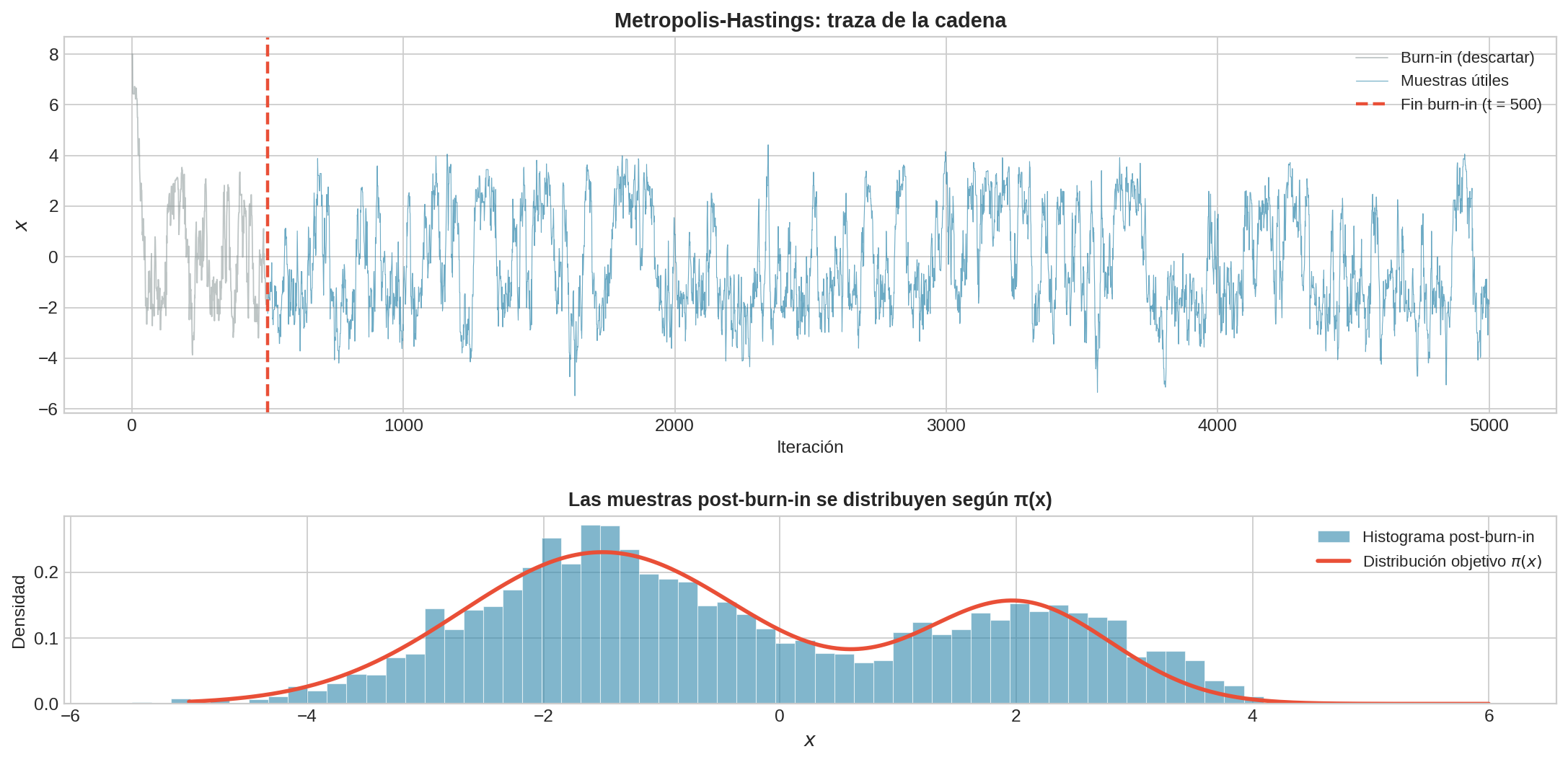
8. Ejemplo: muestrear de una mezcla de Gaussianas
Supongamos que queremos muestrear de una distribución bimodal:
$$\pi(x) \propto 0.4 \cdot e^{-\frac{(x-2)^2}{2 \cdot 0.8^2}} + 0.6 \cdot e^{-\frac{(x+1.5)^2}{2 \cdot 1.2^2}}$$
No podemos calcular la constante de normalización $Z$. Pero podemos evaluar $\tilde{\pi}(x)$ para cualquier $x$. Eso basta para Metropolis-Hastings.
Traza paso a paso
Usamos propuesta simétrica: $y = x + \varepsilon$, $\varepsilon \sim \mathcal{N}(0, 0.8^2)$.
| Paso | Estado $x$ | Propuesta $y$ | $\tilde{\pi}(y)/\tilde{\pi}(x)$ | $u$ | ¿Acepta? | Siguiente |
|---|---|---|---|---|---|---|
| 0 | 0.0 | — | — | — | — | 0.0 |
| 1 | 0.0 | 0.53 | 0.87 | 0.42 | Sí (0.42 < 0.87) | 0.53 |
| 2 | 0.53 | -0.24 | 1.15 | — | Sí ($\alpha = 1$, más probable) | -0.24 |
| 3 | -0.24 | -1.88 | 0.71 | 0.89 | No (0.89 > 0.71) | -0.24 |
| 4 | -0.24 | 0.41 | 0.82 | 0.15 | Sí (0.15 < 0.82) | 0.41 |
| 5 | 0.41 | 1.73 | 1.42 | — | Sí ($\alpha = 1$) | 1.73 |
Lectura de la traza:
- Paso 2: $\tilde{\pi}(y) > \tilde{\pi}(x)$ — nos movemos a un lugar más probable → aceptamos siempre ($\alpha = 1$)
- Paso 3: $\tilde{\pi}(y) < \tilde{\pi}(x)$ y el dado $u = 0.89$ es mayor que $\alpha = 0.71$ → rechazamos. La cadena se queda en $-0.24$.
- Paso 5: propuesta hacia la moda en $x = 2$ → más probable → aceptamos
Con suficientes pasos (miles), el histograma de las muestras se ajusta a la distribución objetivo $\pi(x)$. La cadena explora ambas modas: pasa tiempo alrededor de $x = -1.5$ y alrededor de $x = 2$, en proporción a sus probabilidades.
9. Conexión con el Módulo 12
MCMC cierra un círculo que empezó en el Módulo 12:
| Módulo 12 (Monte Carlo) | Módulo 19 (Cadenas de Markov) | MCMC |
|---|---|---|
| Muestras i.i.d. | Muestras dependientes | Muestras dependientes de $\pi$ |
| LLN: $\frac{1}{n}\sum f(X_i) \to \mathbb{E}[f]$ | Teorema ergódico: $\frac{1}{T}\sum f(X_t) \to \mathbb{E}_\pi[f]$ | Combinación: muestreo + promedios |
| Requiere saber muestrear de $p$ | Dada $\mathbf{P}$, encuentra $\pi$ | Dada $\pi$, construye $\mathbf{P}$ |
El Módulo 12 ya incluye notebooks de aplicación con MCMC:
- 04 — Inferencia Bayesiana: rejection sampling, importance sampling, preview de MCMC
- 06 — Modelo de Ising: Metropolis-Hastings en su aplicación original, transiciones de fase
Lo que este módulo aporta es la fundamentación teórica: ahora sabes por qué MCMC funciona — es una cadena de Markov ergódica cuya distribución estacionaria es la distribución objetivo. El teorema ergódico garantiza la convergencia. El burn-in se explica por el argumento de acoplamiento.
← Aplicaciones · Siguiente: Notebooks de práctica — ver índice del módulo